.png)
本文将详细介绍如何基于 Ollama 完成本地模型搭建,主要过程包含以下三部分:
第一:带有GPU的服务器;
第二:基于GPU服务器完成1Panel安装部署;
第三:基于1Panel服务器完成GPU资源调度设置;
第四:基于1Panel 完成 Ollama 部署;
第五:基于AI/模型管理完成本地模型Qwen3.6:27b配置;
第六:基于OpenClaw完成本地模型调用验证。
以下我们逐一按照该步骤详细说明。
步骤一:准备带有GPU的服务器
本次介绍我选择的是腾讯的GPU服务器,其中基础配置参见如下:
实例规格:GPU计算型GN1
操作系统:Ubuntu Server 22.04 LTS 64位
CPU/内存:10核/40GiB
GPU:1 * NVIDIA V100
公
安全组:18888(1Panel应用端口)、11434(Ollama端口)


步骤二:完成 1Panel 的安装部署及面板配置
参见 1Panel 在线文档输入以下命令完成 1Panel 安装:
bash -c "$(curl -sSL https://resource.fit2cloud.com/1panel/package/v2/quick_start.sh)"提醒:通过 sudo su - 切换到 root 用户
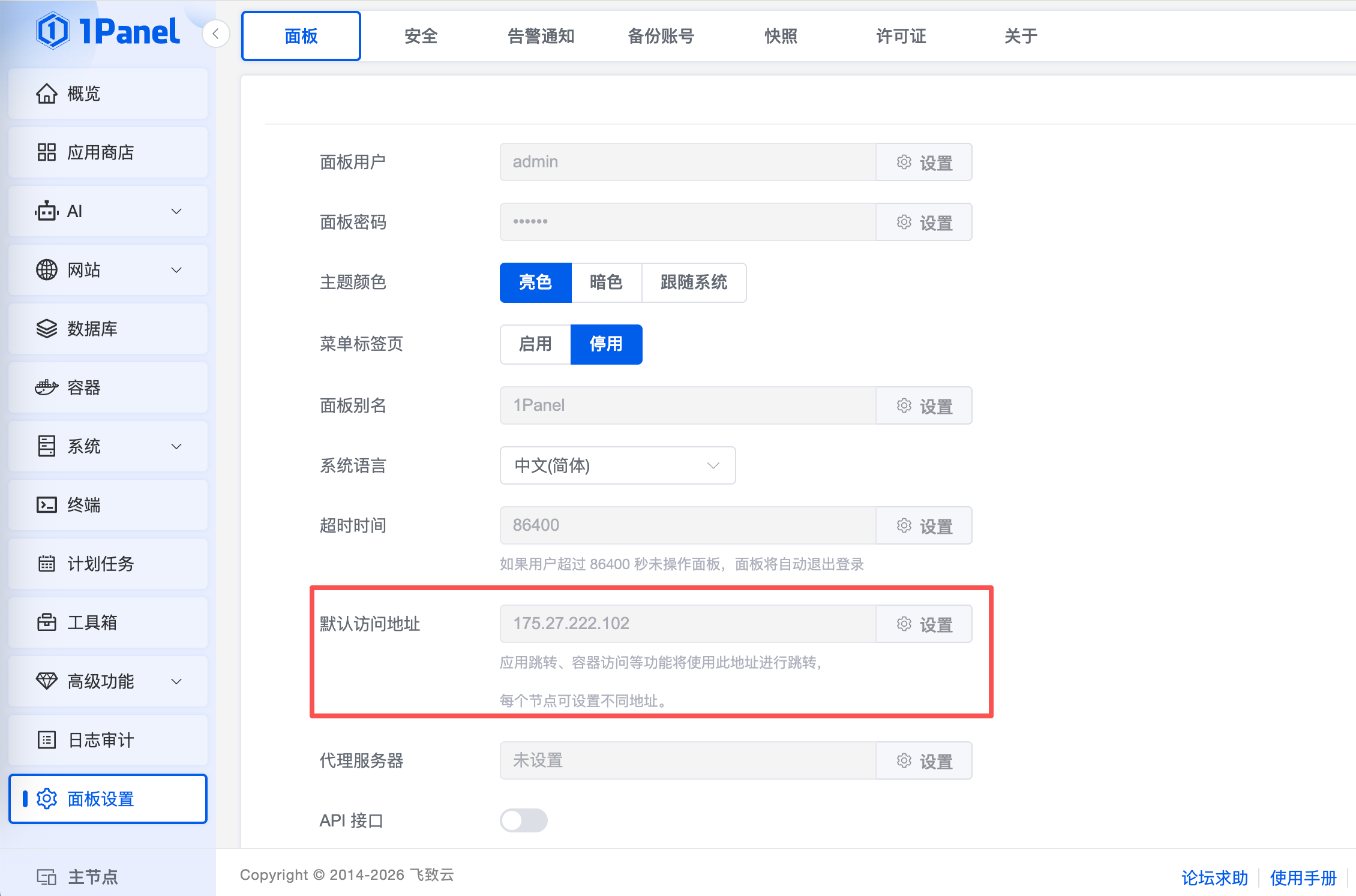
完成安装后,进入面板配置输入公网IP作为默认访问地址:
步骤三:基于GPU服务器完成GPU资源配置
首先 安装NVIDIA容器镜像。为了在Docker容器中能够使用GPU资源,我们需要安装NVIDIA的容器镜像,参照如下命令行逐个执行操作:
命令行1:添加NVIDIA容器工具仓库与签名(确保网络正常访问GitHub)
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list命令行2:启用仓库中的experimental组件(可选)
sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list命令行3:更新软件源
sudo apt-get update命令行4:安装nvidia-container-toolkit
s然后继续配置Docker镜像使用NVIDIA。安装完容器镜像后,需要配置Docker以使用NVIDIA的GPU资源,并且重启Docker服务。
命令行1:配置Docker以使用NVIDIA
s命令行2:重启Docker
s
步骤四:基于 1Panel 完成 Ollama 安装
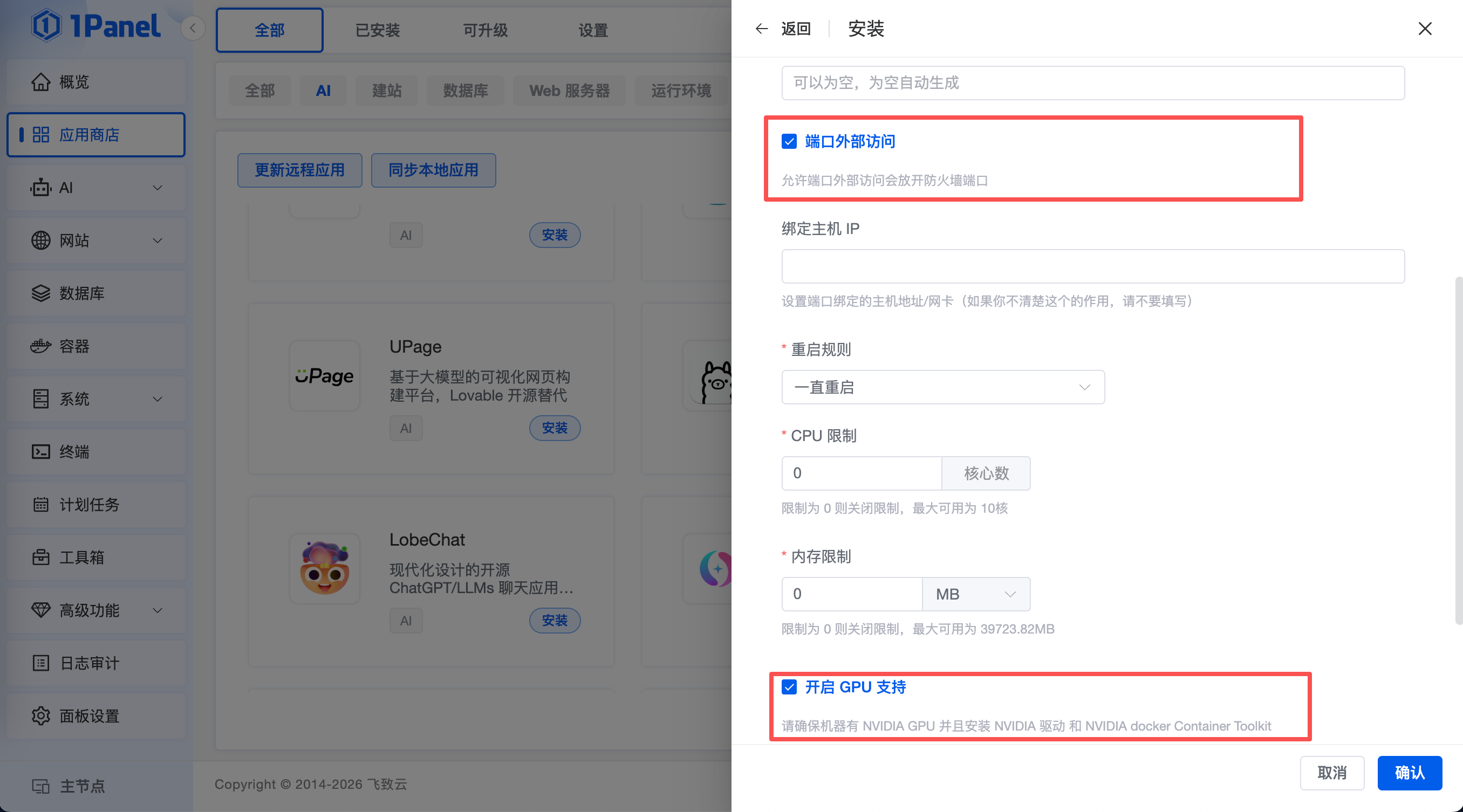
进入 1Panel 的应用商店搜索 Ollama,点击安装,开启端口外部访问,开启GPU支持,记得云上服务器开通 11434 的端口。
点击链接地址显示 Ollama is running,则代表部署成功
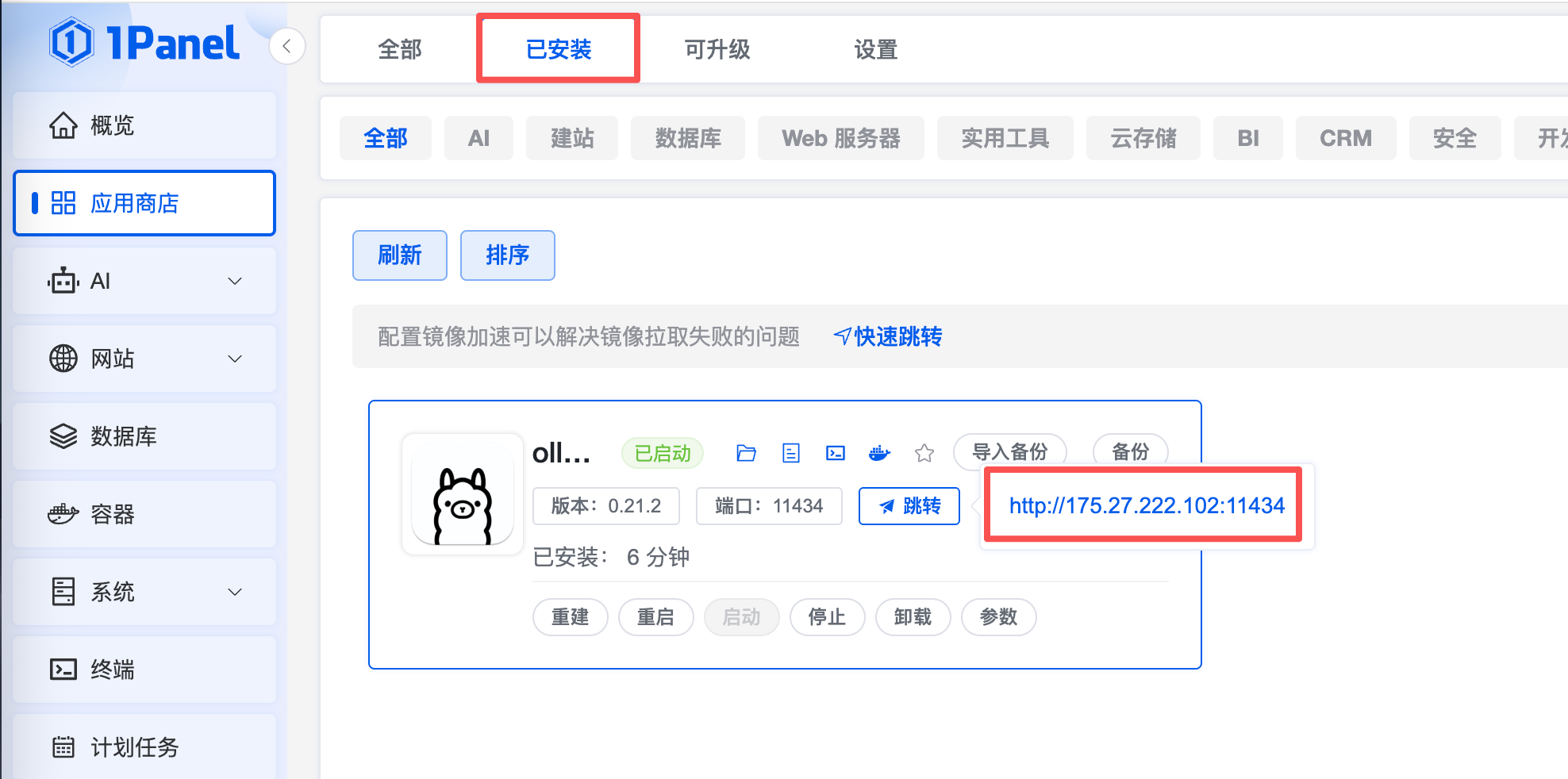
步骤五:基于 Ollama 加载 Qwen3.6 27B 的模型
Ollama 部署完成后,我们继续基于 1Panel 来完成基于 Ollama本地 qwen3.6:27b 模型的加载部署,参照如下步骤即可实现。
步骤一:创建 gpt-oss 模型。在1Panel中依次选择“AI”→“模型”,点击“添加模型”按钮。
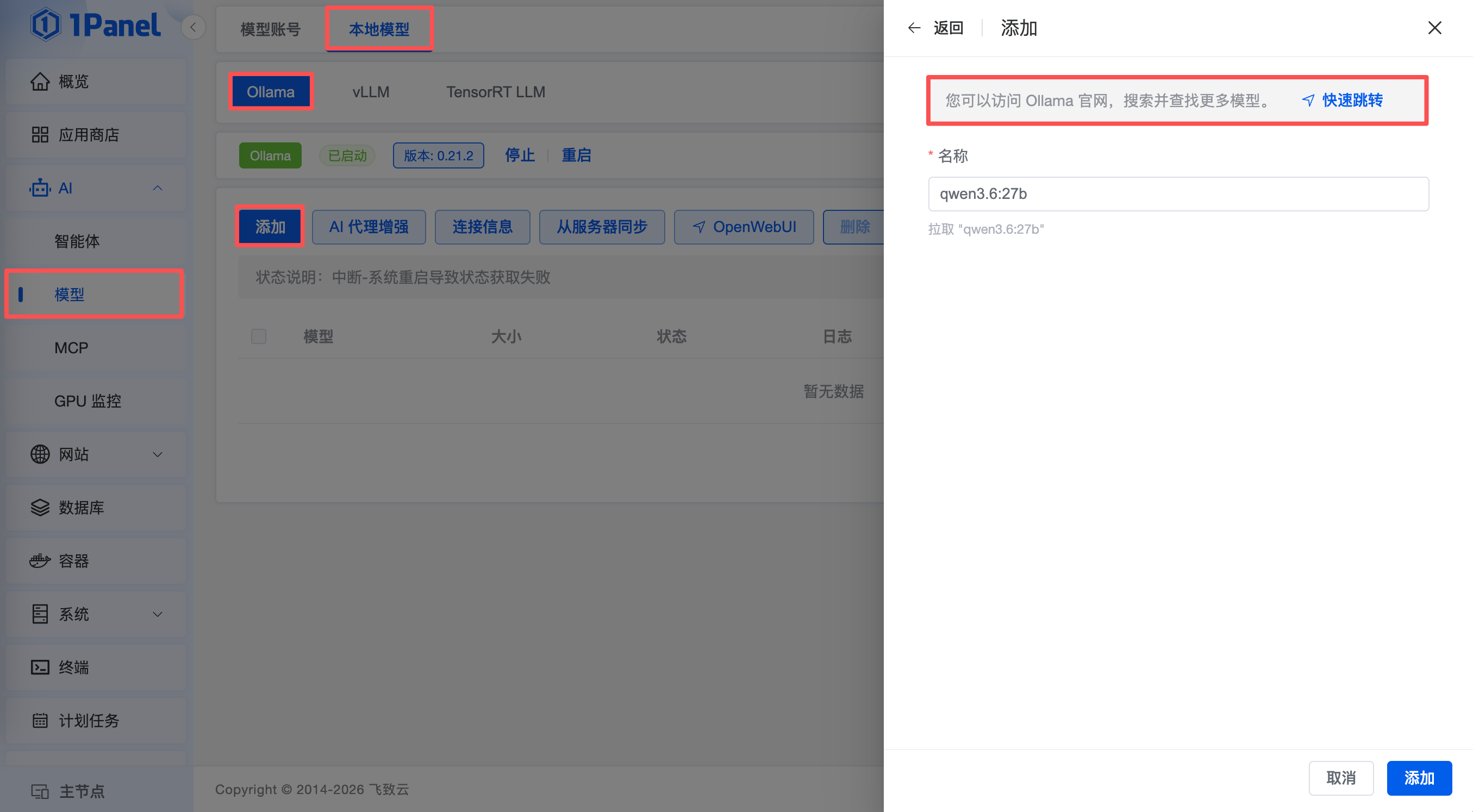

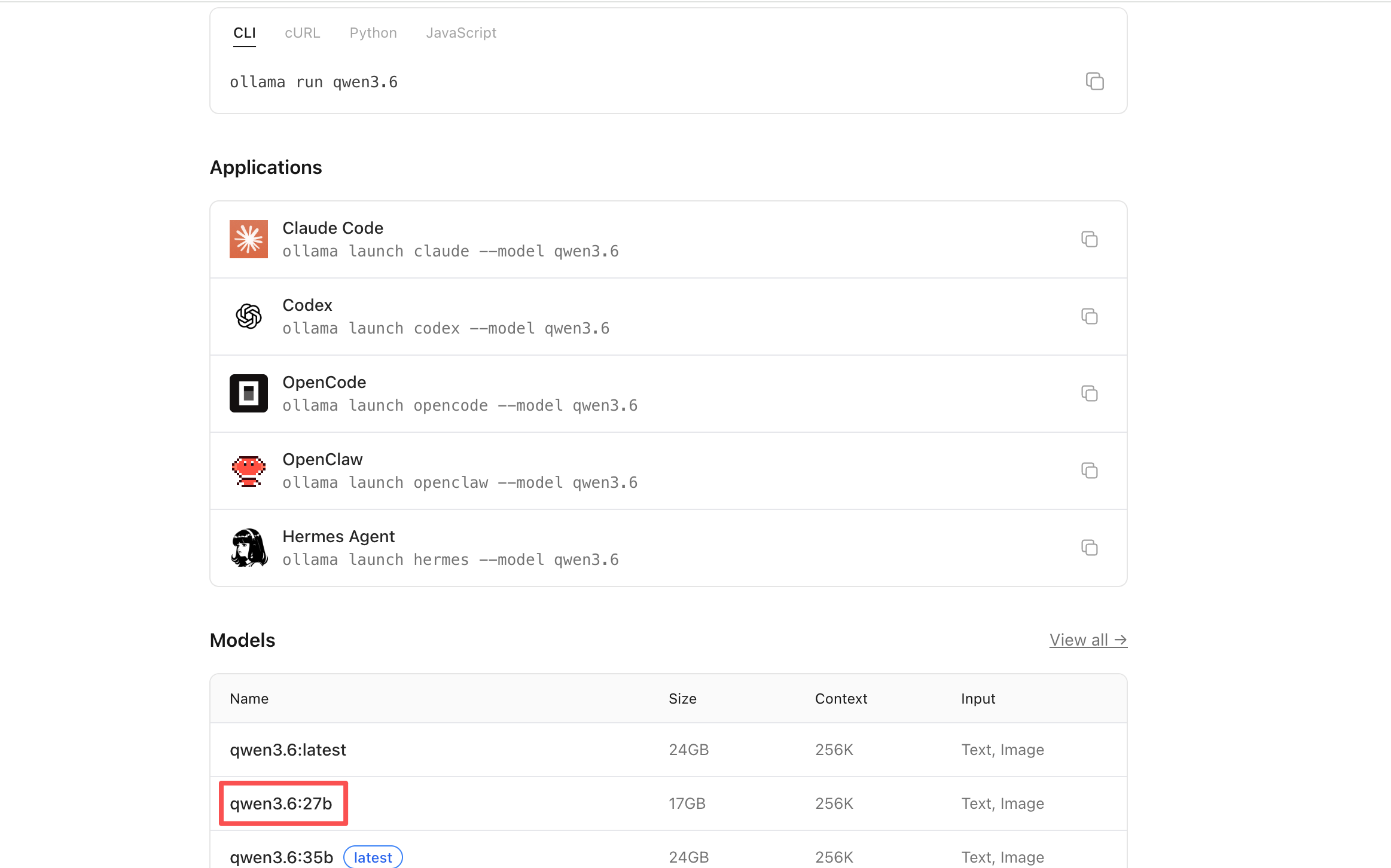
步骤二:加载模型。如下图所示点击「快速跳转」访问Ollama官网,输入模型名称“qwen3.6”快速搜索到qwen3.6:27b模型,并复制模型ID“qwen3.6:27b”输入到「名称」,同时点击“添加”按钮开始加载模型文件。这里加载模型大概需要20至30分钟。


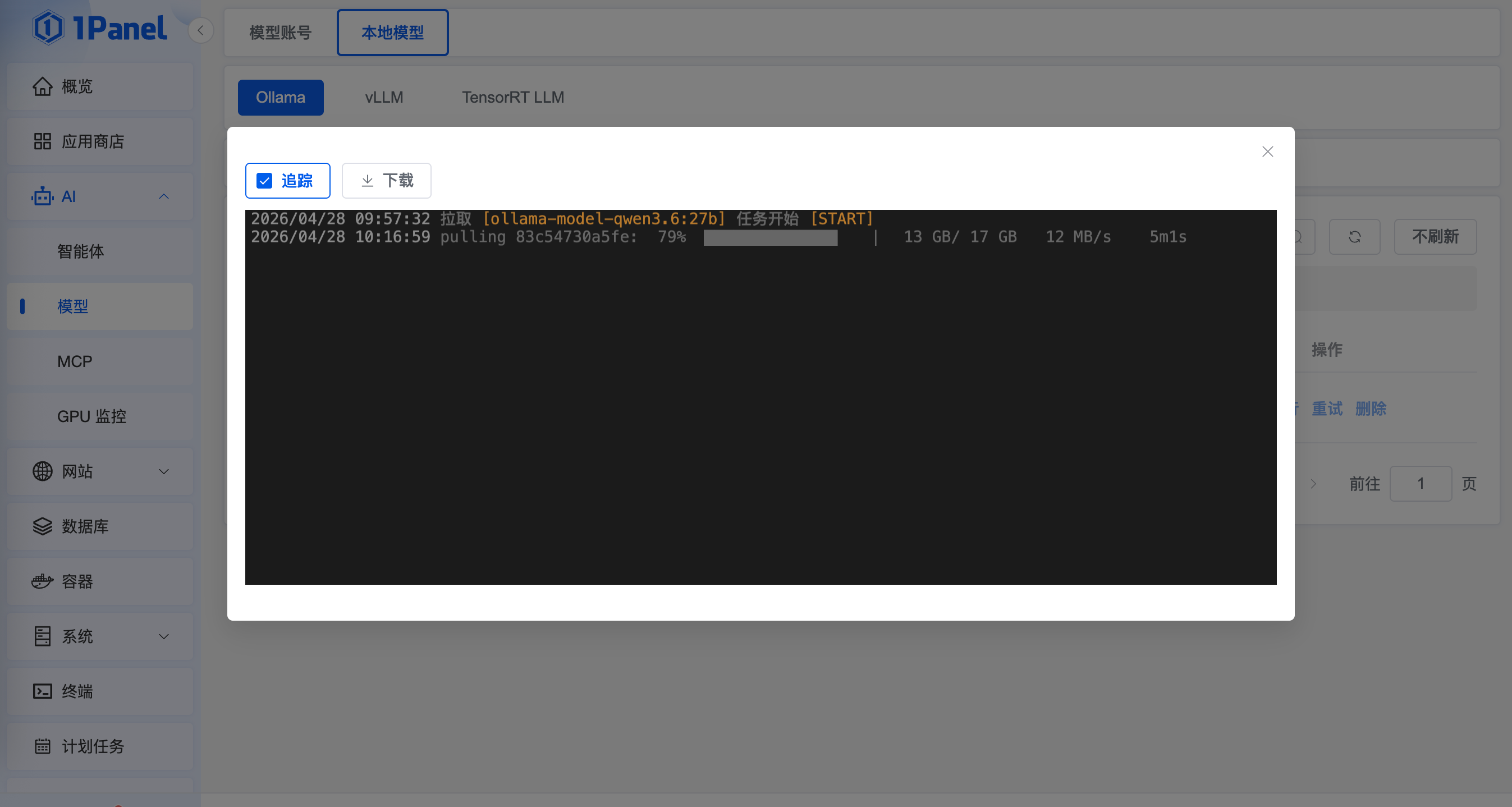
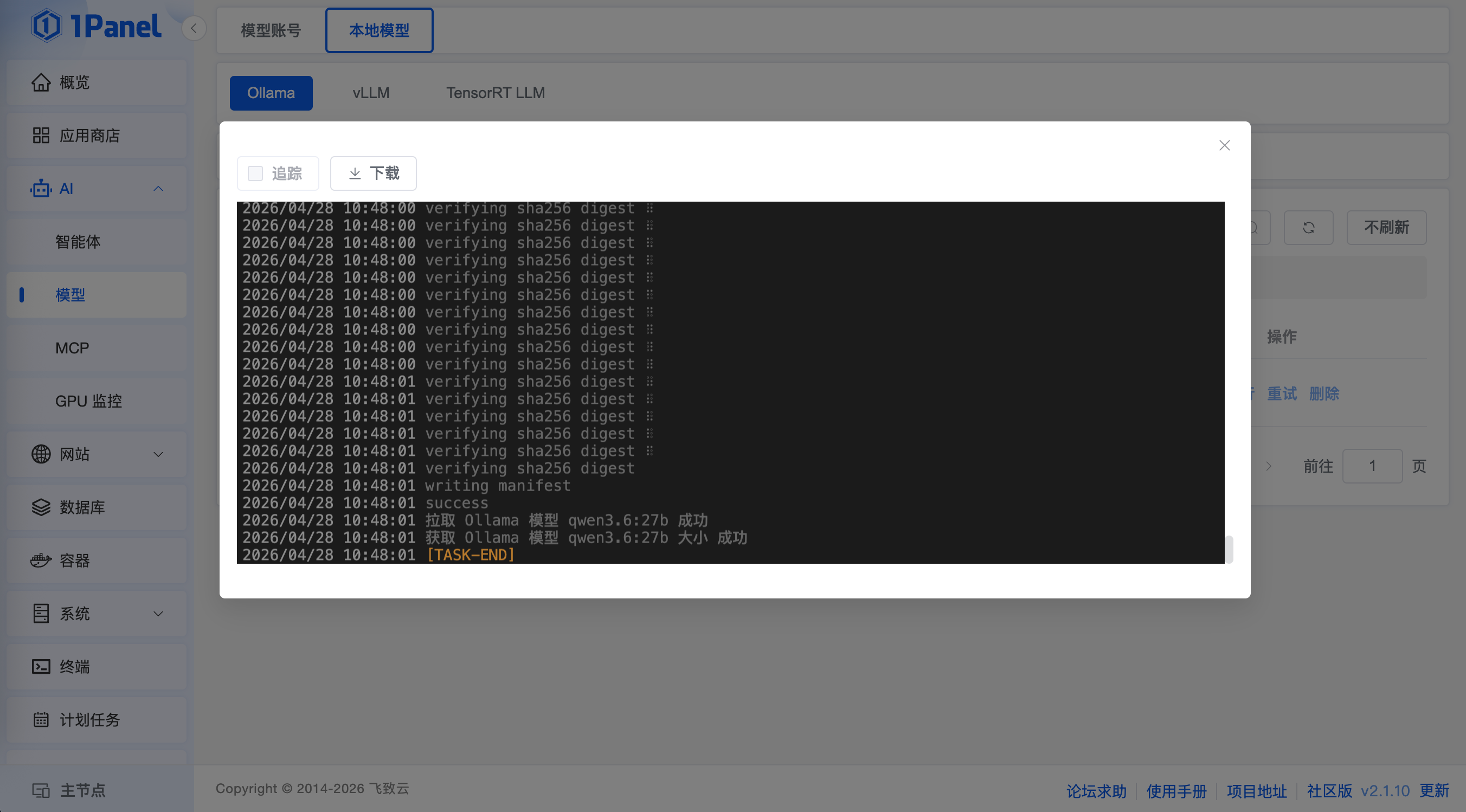
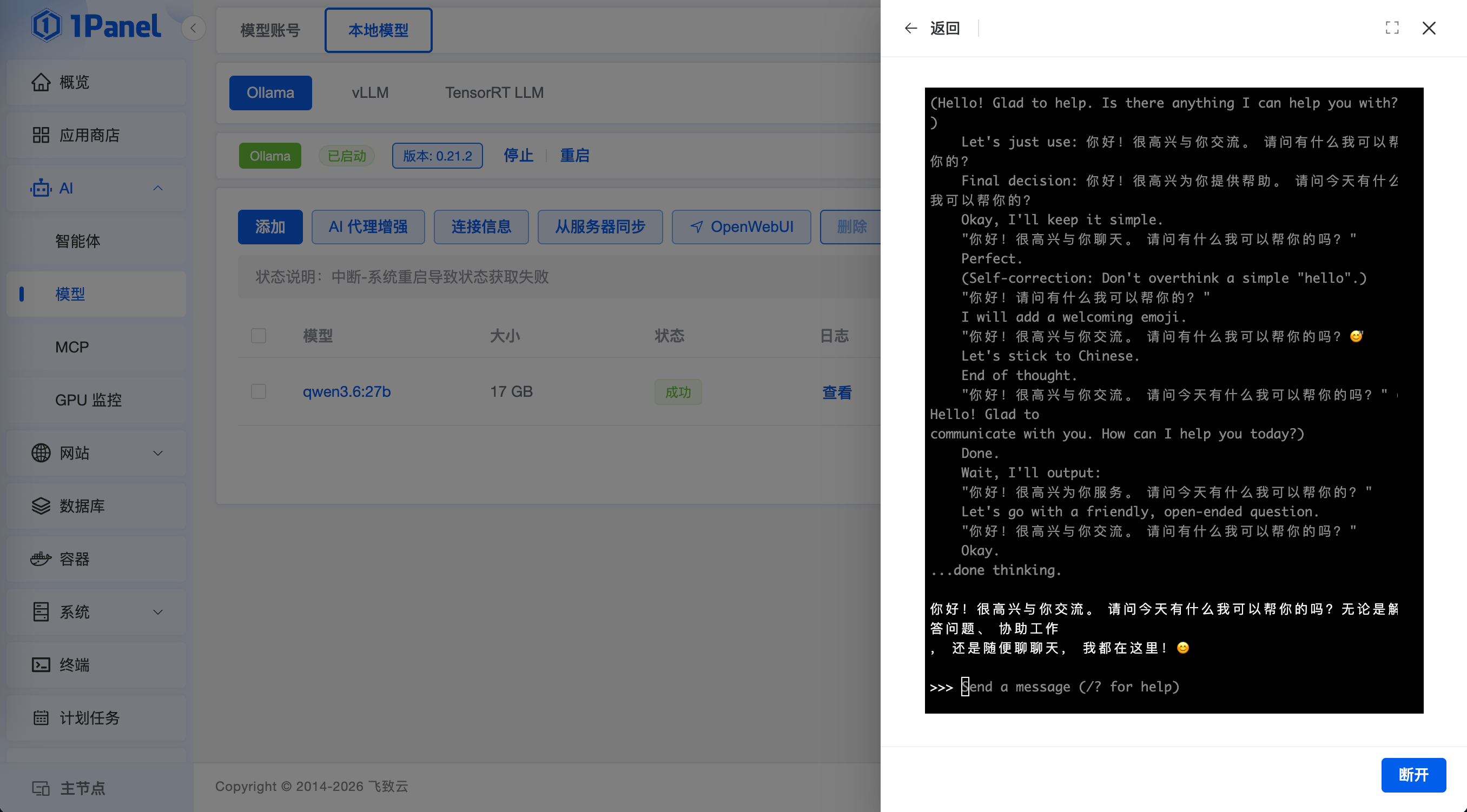
步骤三:模型运行确认。当模型列表中的“状态”项更新为“成功”后,可以点击运行验证模型部署效果,如果能够正常对话则代表模型已经加载成功,如下图所示:

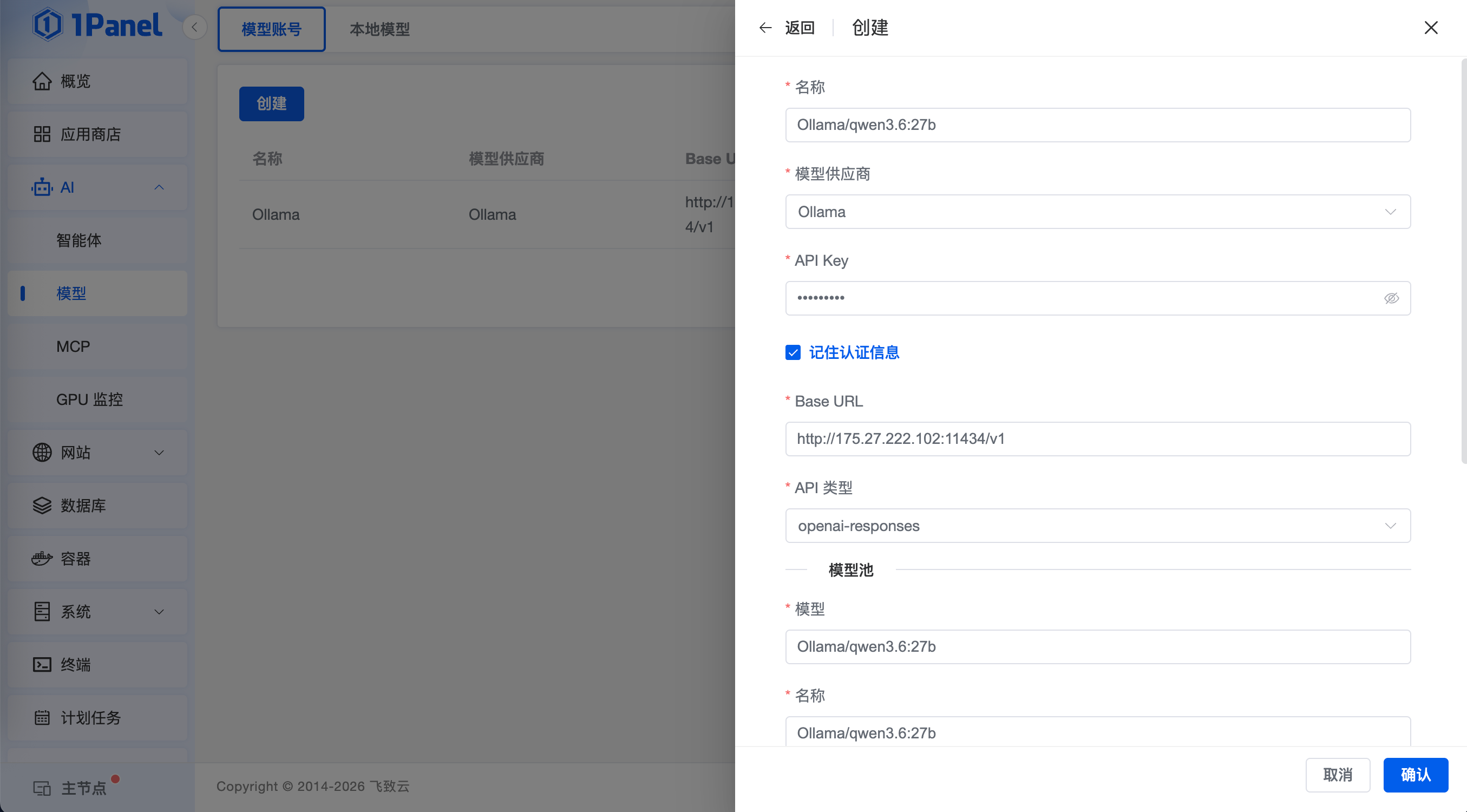
步骤四:基于模型账号管理将刚才创建的 ollama/qwen3.6:27b 本地模型
■ 名称:自定义;
■ 模型供应商:下拉选择“Ollama”;
■ 模型API Key:本地模型输入任意字符即可;
■ Base URL:输入按照上述步骤部署的 Ollama 应用的地址,即 http://IP:11434/v1即可;
■ API 类型:保持默认即可 ;
■ 模型池:逐个输入模型以及模型名称,按照Ollama/qwen3.6:27b即可,即刚才通过Ollama加载qwen3.6:27b,与模型管理处保持一致即可;如果Ollama有更多的模型,则可以逐个在模型池中加入。
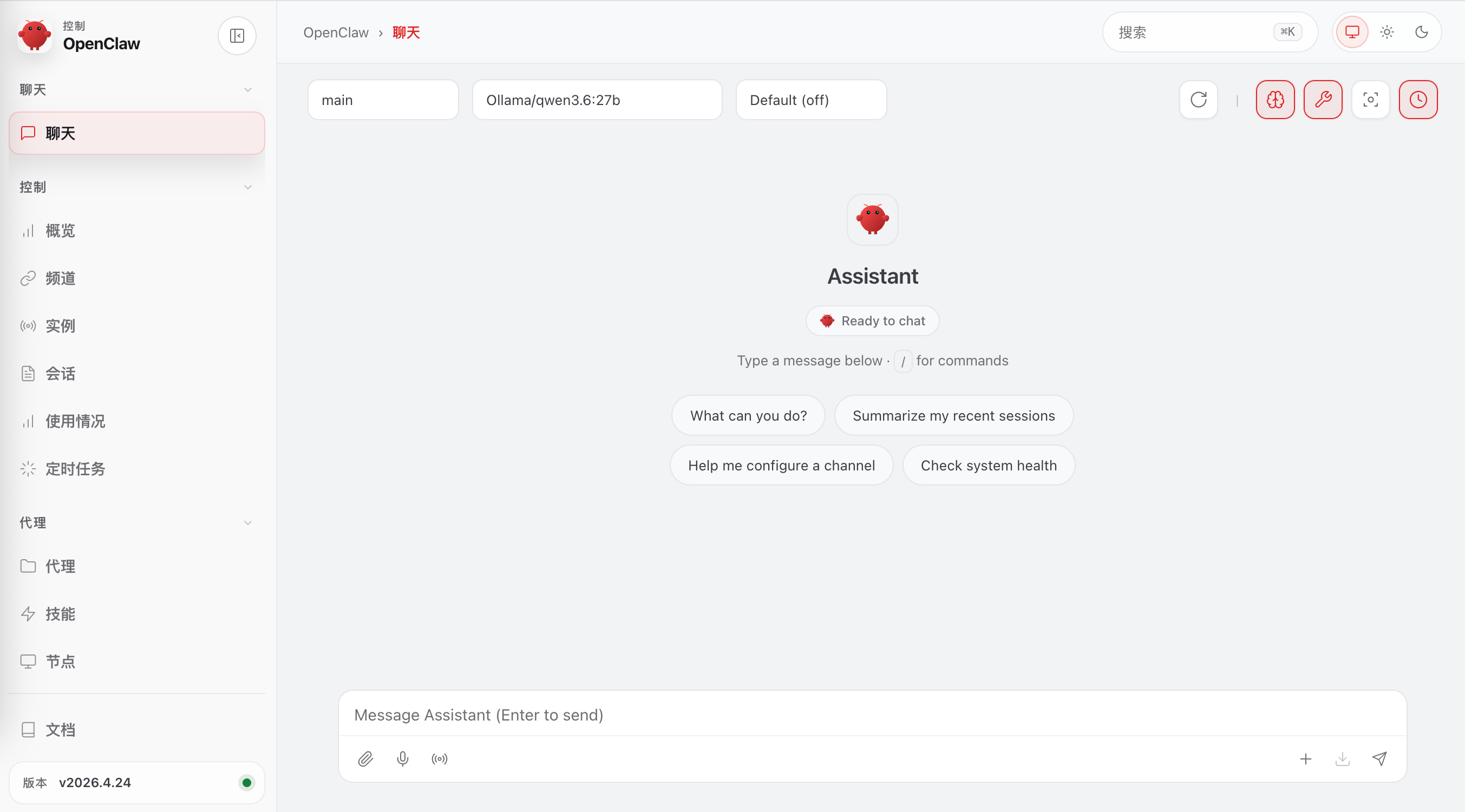
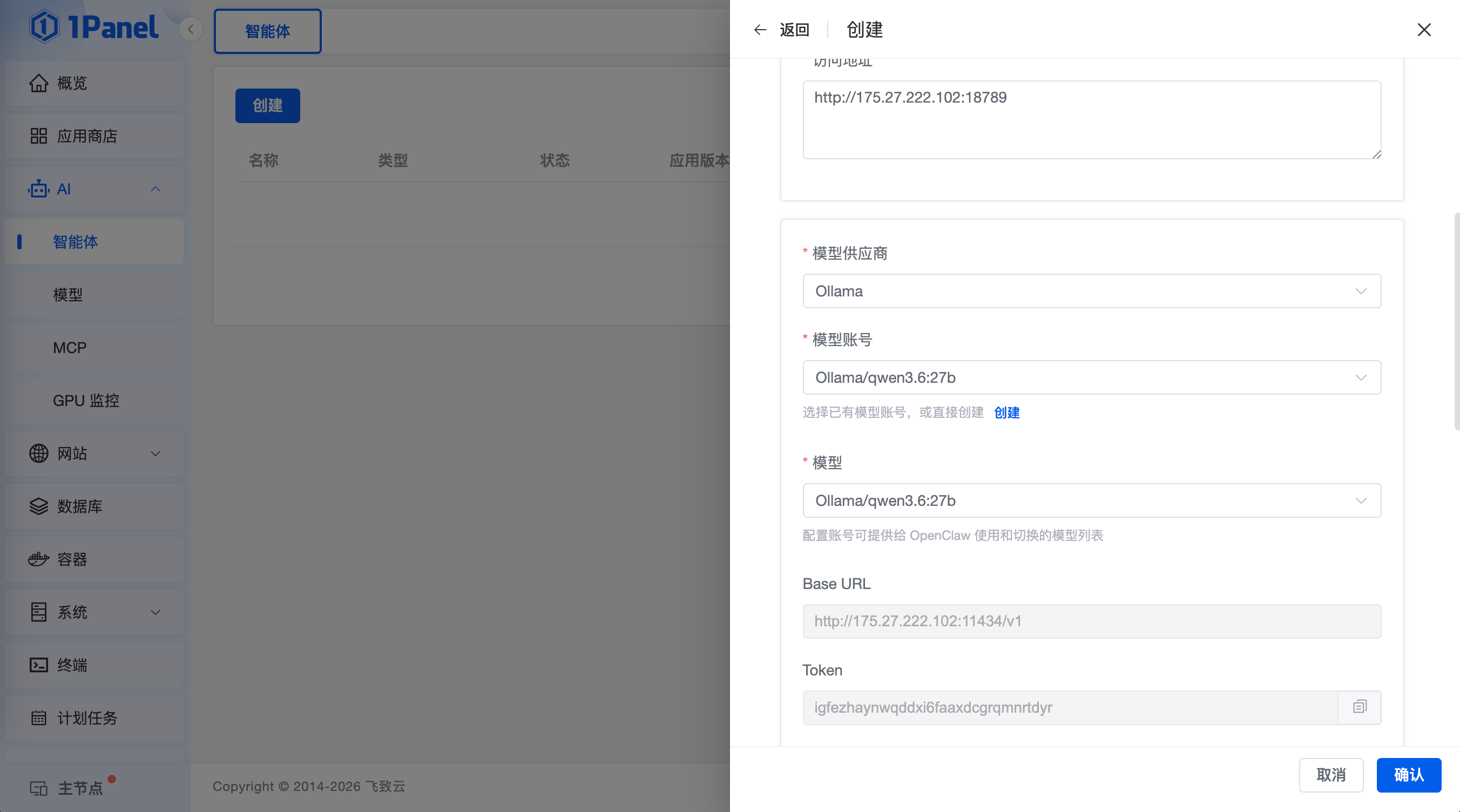
步骤六:以 OpenClaw 为例使用本地模型验证本地模型效果
通过 AI/智能体完成 OpenClaw 部署,点击创建,智能体类型选择 OpenClaw,自定义名称,确保18789端口/防火墙已经开通,同时选择Ollama模型供应商,选择刚才创建的模型账号以及模型名称,点击创建,开始启动 OpenClaw 智能体应用。
1-2分钟后系统会自动完成镜像拉取以及 OpenClaw 应用安装,如下图所示:
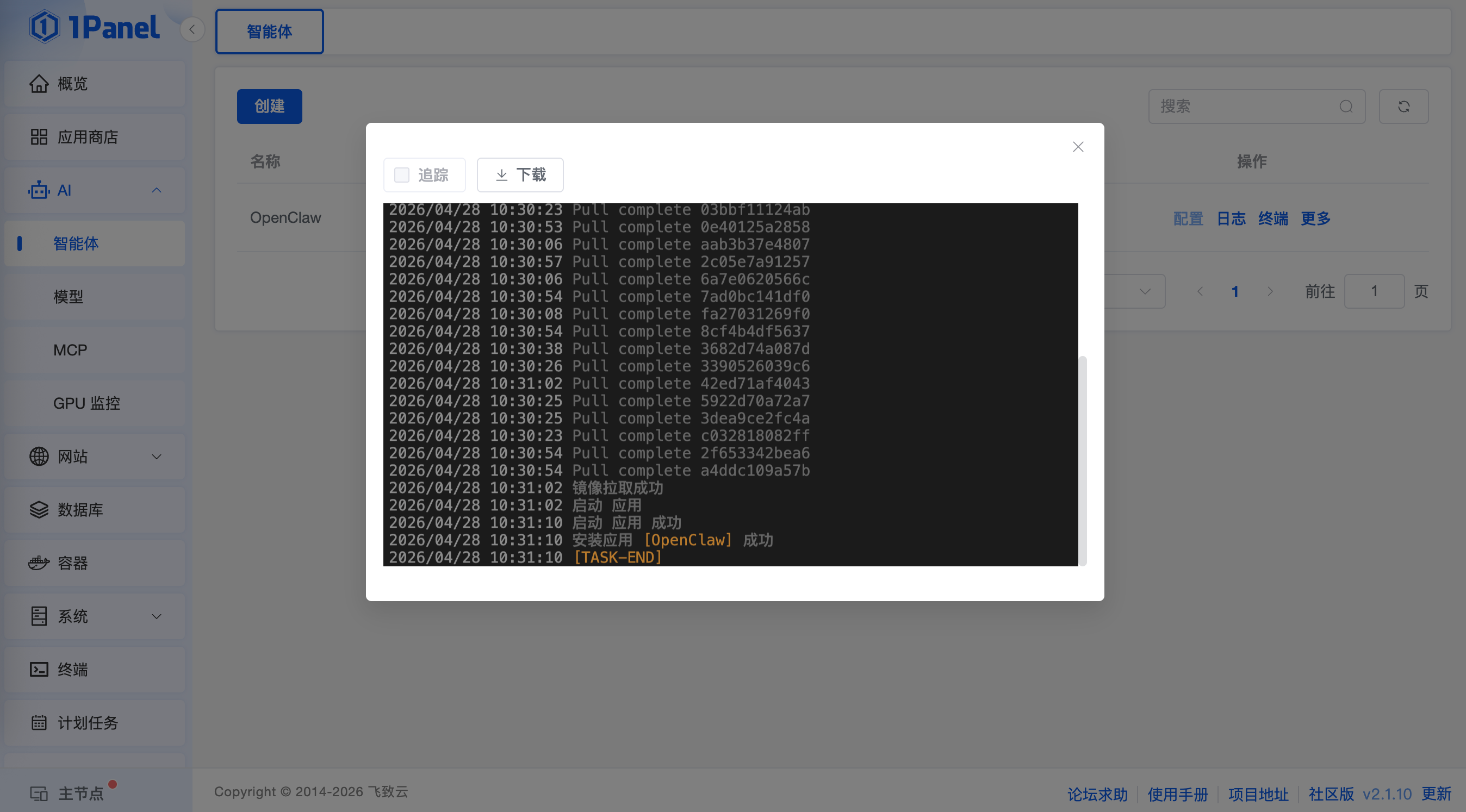
安装完成后,我们直接点击 WebUI 验证通过 OpenClaw 验证本地模型效果,这样同时也可以让我们的OpenClaw 不限 token得使用起来。
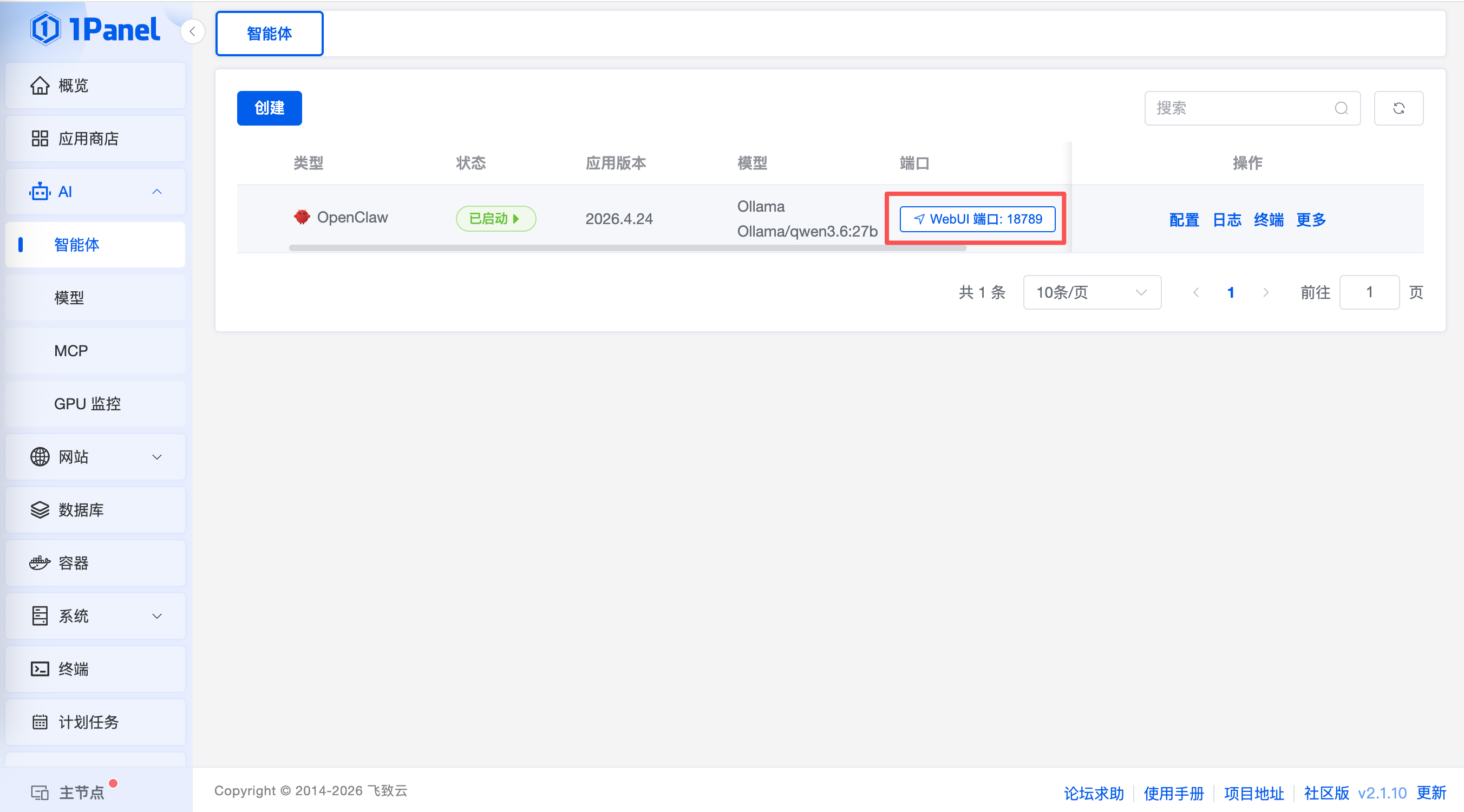
点击后即进入OpenClaw主页面