用 OpenClaw 后,需要重新理解“本地大模型”
引言:近期, “大龙虾” OpenClaw 引爆全球互联网,以其面向本地与私有化场景的架构设计、对工具调用与自动化执行的良好支持,在技术社区引发广泛关注,逐步成为开发者和技术团队构建“可长期运行的个人助理”的重要选择。本文将围绕 OpenClaw 的实际落地场景,系统分析其对模型底座与算力平台的核心要求,并结合本地部署实践,给出最适配的参考方案(截止到26年2月)。
一、OpenClaw 应用正当时
过去几年,大模型的主要形态,其实只有一种:一个会聊天的机器人。它能回答问题、能写点代码、能总结文档,但本质上始终停留在“对话层”。
而 OpenClaw 的横空出世,让很多人第一次意识到:AI 不一定只是对话窗口,它可以直接参与到执行的流程。OpenClaw 主打 “本地部署 + 多渠道交互 + 任务执行”,让用户通过常用聊天工具指挥 AI 完成文件操作、浏览器控制、定时任务等自动化工作。所以很多人在第一次跑通 OpenClaw Demo 的时候,都会有一个相同的感受:
“AI 终于不像 PPT 里的东西,它开始有‘干活感’了。“
二、OpenClaw 落地过程中暴露的共性问题
在实际引入 OpenClaw 的过程中,很多团队很快发现,OpenClaw 本身提供了清晰的能力边界和灵活的扩展方式,但一旦进入真实场景,模型的差异会被迅速放大。
模型选型混乱,国内网络环境加剧落地门槛
当前可选的大模型数量繁多,能力侧重点各不相同,有的偏代码,有的偏推理,有的在对话上表现突出,却在工具调用时不够稳定。对 OpenClaw 而言,这种差异直接影响任务的可控性和执行成功率。
同时,在国内环境下,网络条件的不确定性也成为绕不开的现实问题。依赖海外模型或跨境 API,往往会引入额外的延迟、抖动甚至不可用风险,使得自动化流程难以长期稳定运行。
公有模型Tokens消耗过快,长期使用成本居高不下
一次对话和任务执行,会多次调用大模型,大模型会持续参与任务分析、决策和校验。多轮推理、长上下文和高并发请求,会迅速放大 Token 消耗,成本曲线陡然上升,甚至超过了原本希望通过自动化节省的人力成本的原始诉求,大家普遍感觉“太贵了”。
数据安全风险突出,与OpenClaw“本地优先”的定位相悖
OpenClaw本身强调“数据默认本地存储、用户掌控数据主权”,这也是其吸引大量隐私敏感型用户的核心优势。但在实际使用过程中,选用公有模型作为支撑,会导致“数据安全闭环被打破”,产生突出的安全风险,与平台本身的定位相悖。当OpenClaw对接公有模型时,用户的对话指令、任务数据(如本地文件内容、网页监控数据、运维日志)需要上传至公有模型的云端服务器进行处理,这就意味着,用户的隐私数据、业务数据可能面临泄露、篡改、滥用的风险——尤其是办公场景中的机密文档、开发运维场景中的服务器信息、个人用户的隐私文件等,一旦上传至云端,无法完全掌控数据流向,可能违反数据安全相关规定,也可能造成个人隐私、企业机密泄露。
综合来看,OpenClaw 落地过程中暴露的选型混乱、成本过高、数据安全三大共性问题,本质上都指向同一个核心——模型底座的选择。OpenClaw 作为“智能体执行平台”,其自身的网关调度、任务拆解、多渠道联动能力已相对成熟,而模型底座作为“决策核心”,直接决定了落地门槛、使用成本与安全水平。本地部署大模型,正在成为 OpenClaw 场景下最现实、也最稳妥的选择。
三、OpenClaw 场景下的本地模型更优解
OpenClaw 对本地支撑模型的核心诉求是:指令拆解精准、工具调用适配性强、推理高效。
笔者结合当前开源生态,重点分析 3 款最新开源的大模型,搭配最优推理框架,探索 OpenClaw 生态全栈私有化部署的更优解。
3.1 OpenClaw 场景下的主流开源模型分析
基于以下几个指标选型模型。
- 部署成本:少花钱,消费级硬件优先。不将 8 卡 H20 这种“巨兽”纳入考虑范围
- 指令拆解:精准拆解自动化任务步骤
- 工具调用:适配OpenClaw常用工具,联动顺畅
- 推理速度:高效响应,适配高频任务
综合考察当前几款主流的开源模型,确适配性,规避选型误区,GLM-4.7-Flash、Qwen3-Coder-Next、Step-3.5-Flash 这三个模型纳入重点考察范围。
| 模型名称 | 部署成本 | 指令拆解 | 工具调用 | 推理速度 |
|---|---|---|---|---|
| GLM-4.7-Flash | 低 | 均衡,基础任务适配,复杂任务精细化不足 | 一般,经常出现工具无法调用问题 | 较快 |
| Qwen3-Coder-Next | 中等 | 精准,可高效拆解各类自动化任务步骤 | 优秀,常规任务可完整执行 | 较慢 |
| Step-3.5-Flash | 中等 | 精准,可高效拆解各类自动化任务步骤 | 优秀,常规任务可完整执行 | 较快 |
* 模型简介:
GLM-4.7-Flash:智谱 AI 开源的 MoE 架构模型,总参数 30B、激活参数 3B,支持长上下文,编码与多跳推理达开源 SOTA,显存占用低适配消费级硬件,支持多框架本地部署。
Qwen3-Coder-Next:阿里千问开源的代码代理专用 MoE 架构模型,总参数 80B、激活参数 3B,支持长上下文,SWE-Bench Verified 准确率 74.2%,专注于长时程、多工具、可交互的真实编程任务。
Step-3.5-Flash:阶跃星辰开源的 MoE 架构模型,总参数 196B、激活参数 11B,支持长上下文,主攻智能体场景的实时推理任务,推理速度快,在代码、智能体任务表现优异,适配本地私有化部署。
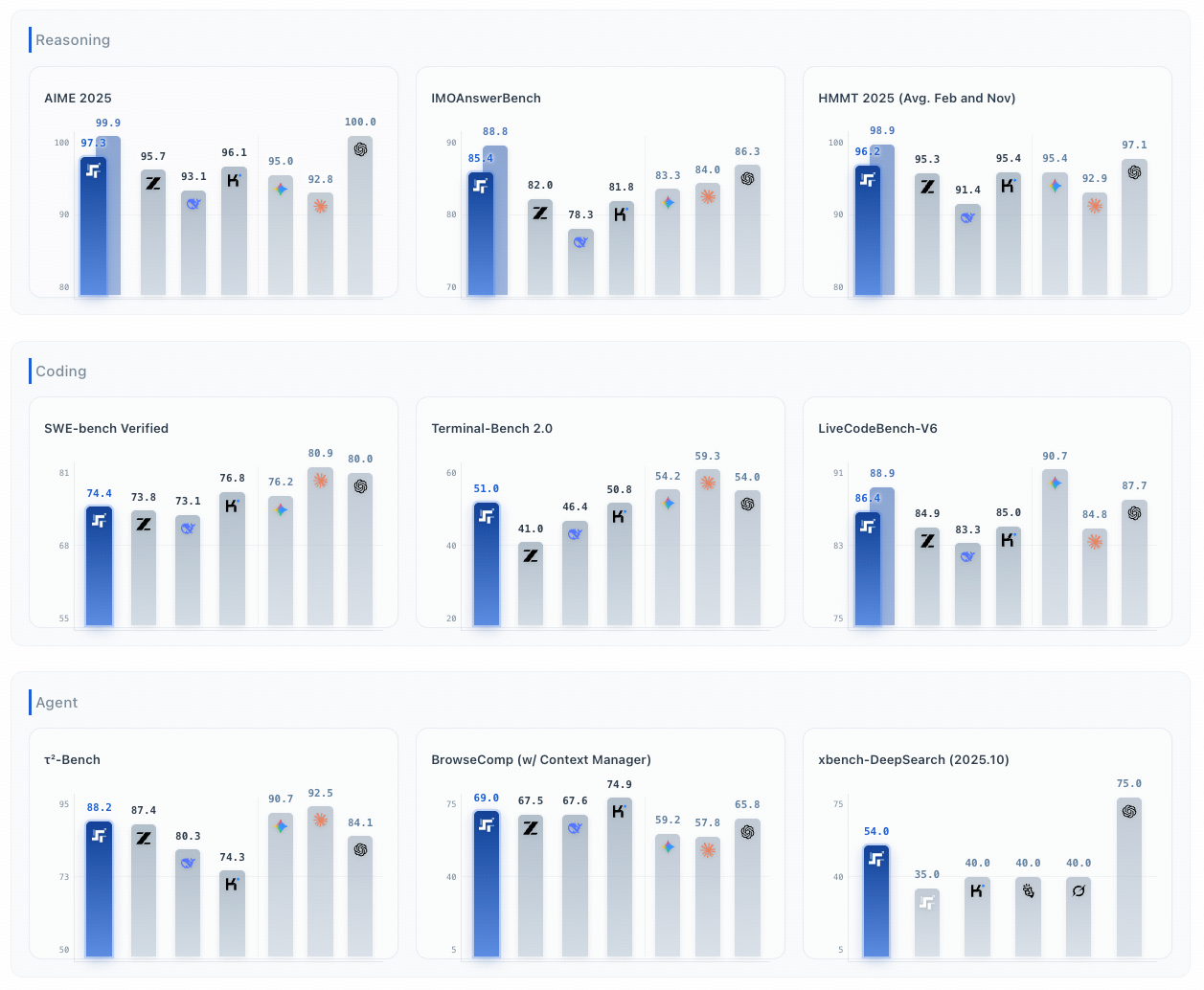
综上,Step-3.5-Flash 是 OpenClaw 接入本地模型的优选方案。
3.2 推理引擎的选型
为充分发挥模型性能,需要搭配合适的推理引擎
| 推理引擎 | 优势 | 劣势 |
|---|---|---|
| Ollama | 部署极简、多系统兼容,非技术用户易上手 | 推理慢、显存利用率低 |
| vLLM | 推理较Ollama快5-10倍,资源利用率高,适配模型MoE架构与OpenClaw联动 | 对 Step-3.5-Flash-Int4 适配性不好 |
| llama.cpp | 基于C/C++实现,性能非常高 | 部署门槛略高 |
选用 llama.cpp 部署 Step-3.5-Flash 大模型
3.3 部署模型
采用搭载 NVIDIA Blackwell GB10 超级 AI 芯片的超聚变 FusionXpark 作为算力底座(128G 统一内存,1 petaFLOP 峰值算力)

3.3.1 下载并格式化模型
a) 安装 Hugging Face CLI
说明:亦可使用hf-mirror、魔搭社区作为下载来源
b) 下载模型
说明:下载 stepfun-ai/Step-3.5-Flash-Int4 量化版本
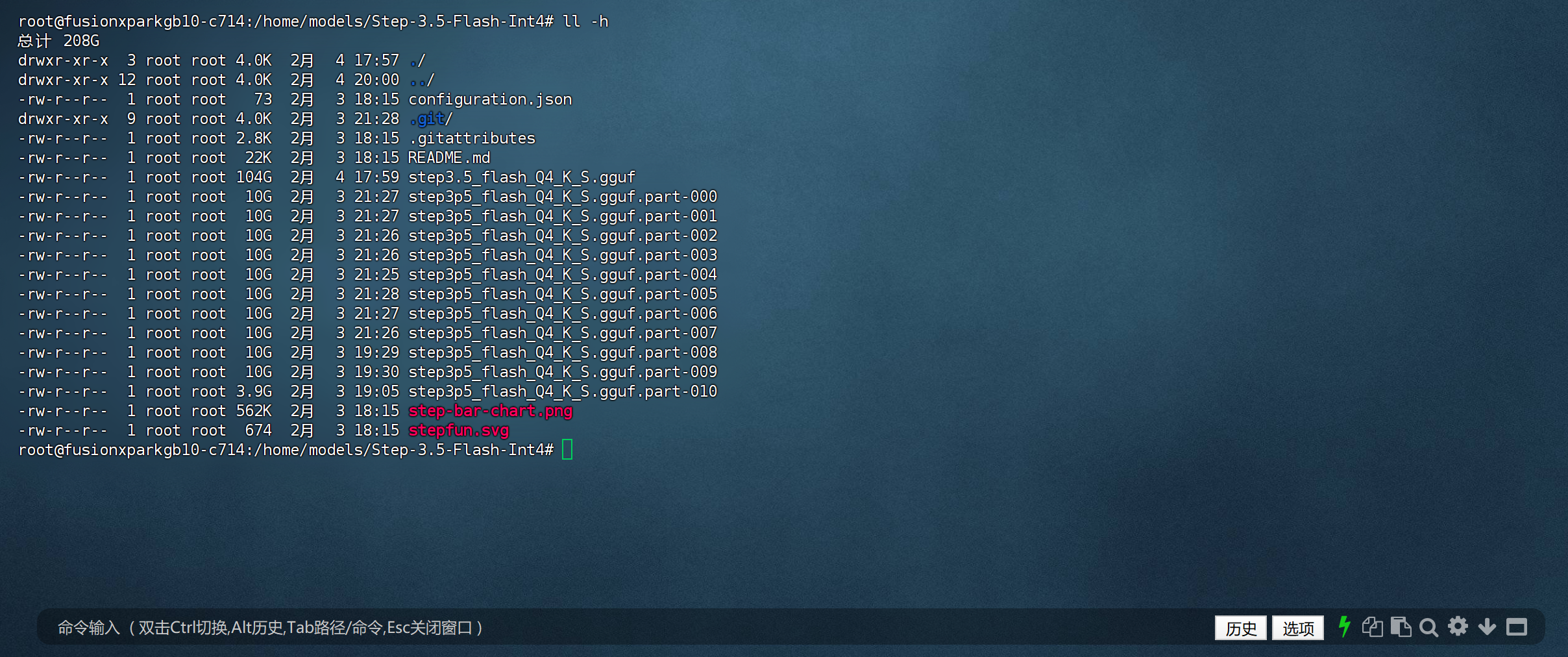
c) 合并分片模型文件
说明:将所有分片合并为完整的.gguf模型文件,llama.cpp 支持的模型格式
3.3.2 构建模型运行环境
方案1)自行构建
说明:耗时较长,编译过程需保证网络稳定。
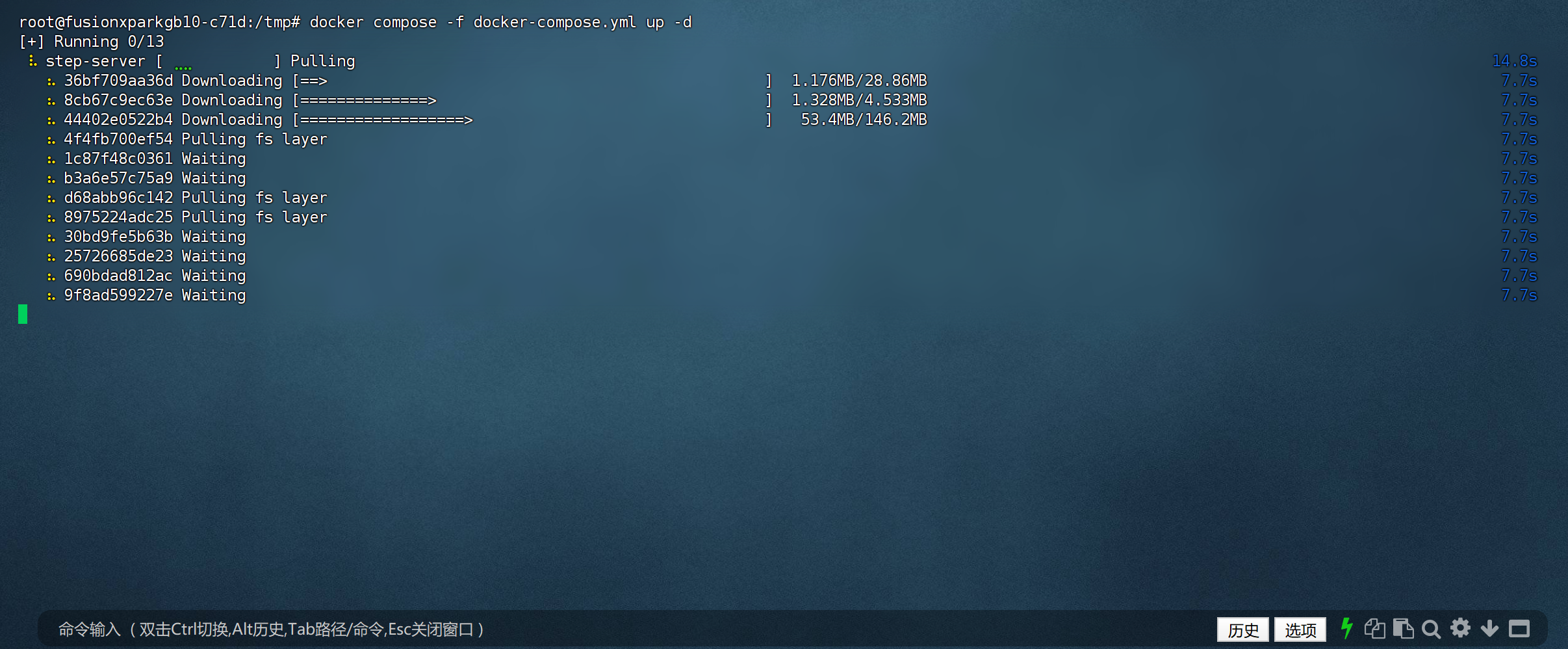
方案2)采用 1Panel 团队构建好的镜像运行(推荐)
a) 拉取镜像
说明:此镜像专为 FusionXpark 优化,可直接运行在 FusionXpark 设备中。
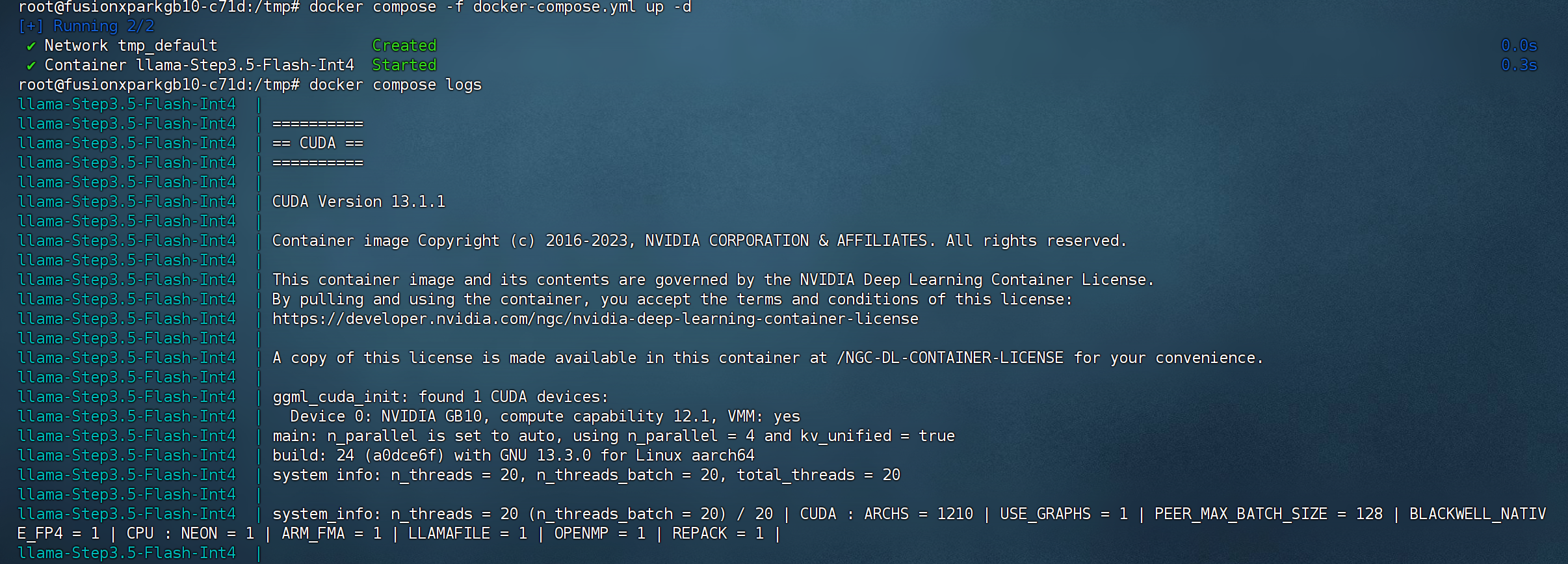
b) 配置模型运行 docker compose 文件
c) 运行模型
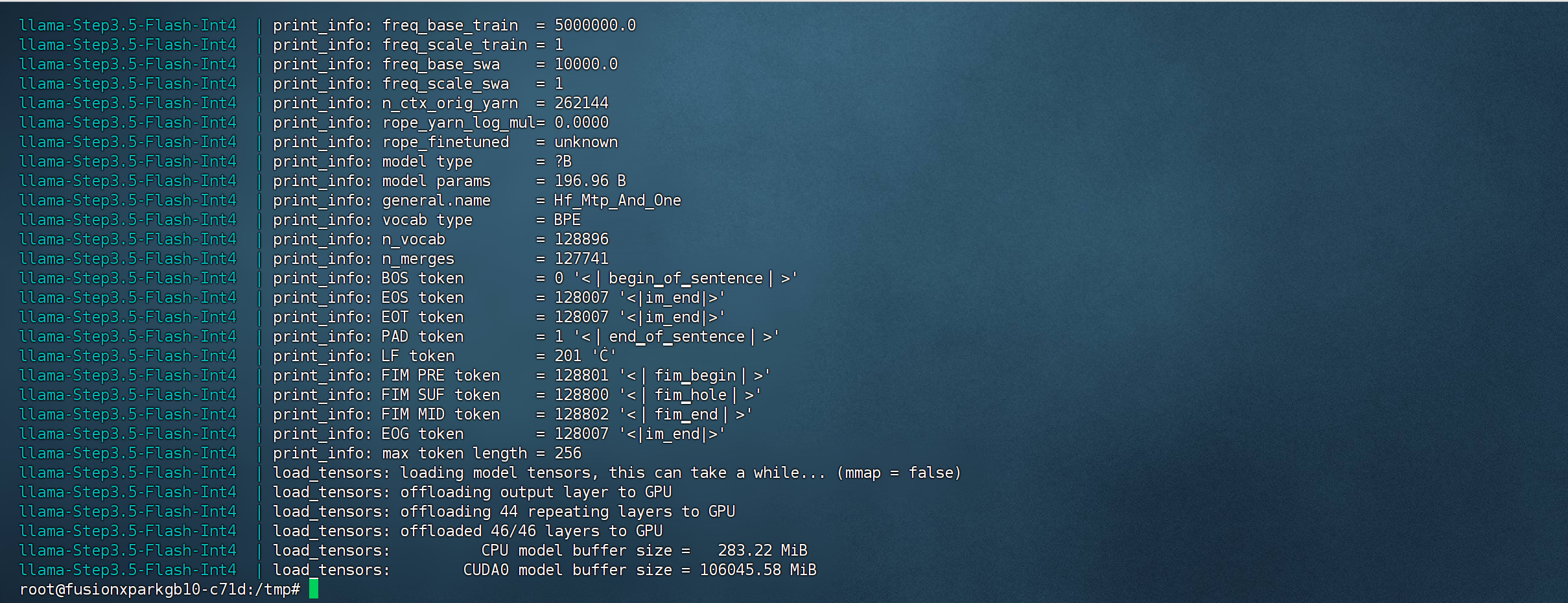
d) 验证模型
访问:http://{IP}:8000
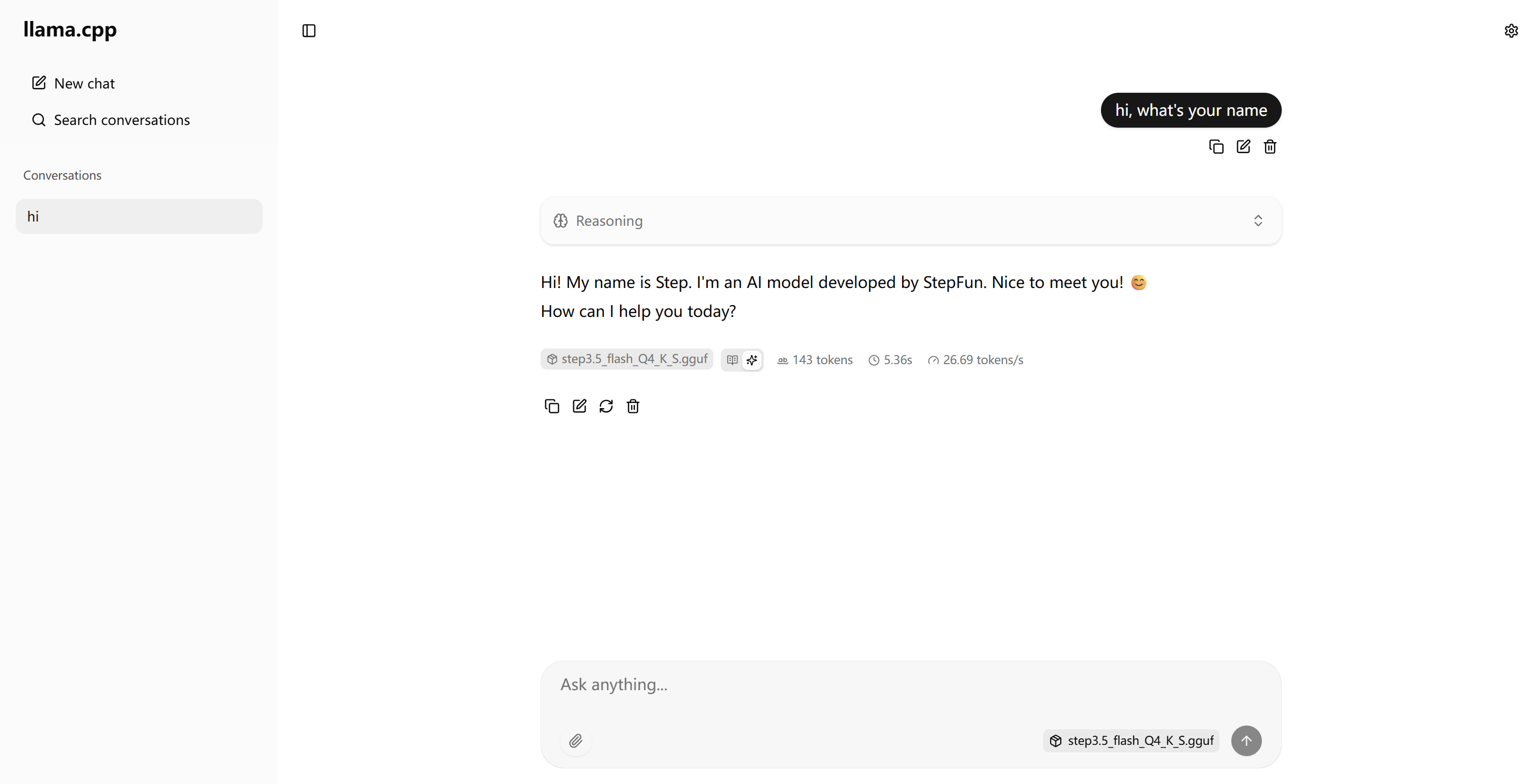
说明:上图为模型交互页面,可看到此模型输出 26.60 tokens/s
四、部署OpenClaw 并接入本地大模型
4.1 部署 OpenClaw
在 1Panel 应用商店一键部署 OpenClaw
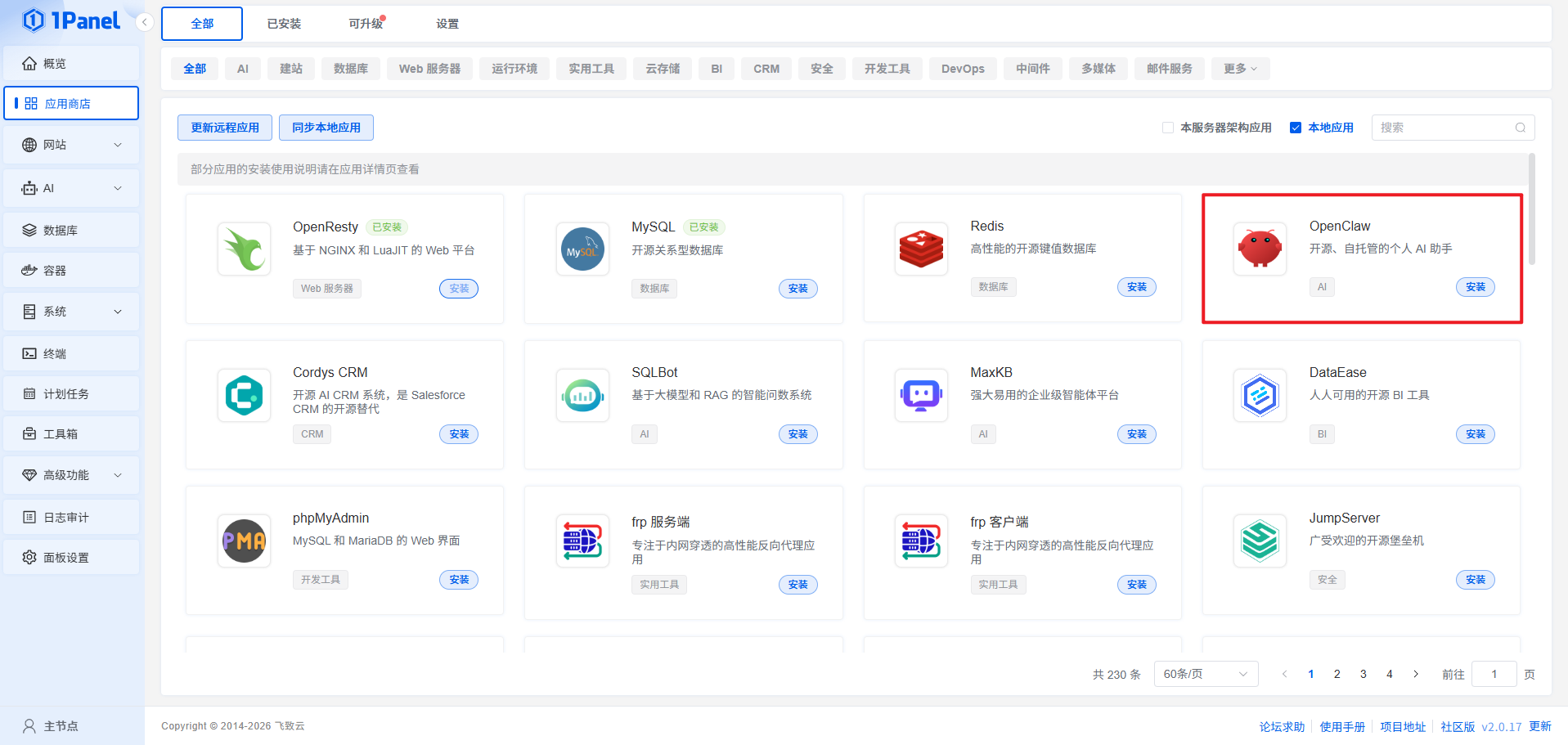
过程不再赘述,详情请参考:https://1panel.cn/docs/v2/user_manual/appstore/openclaw/
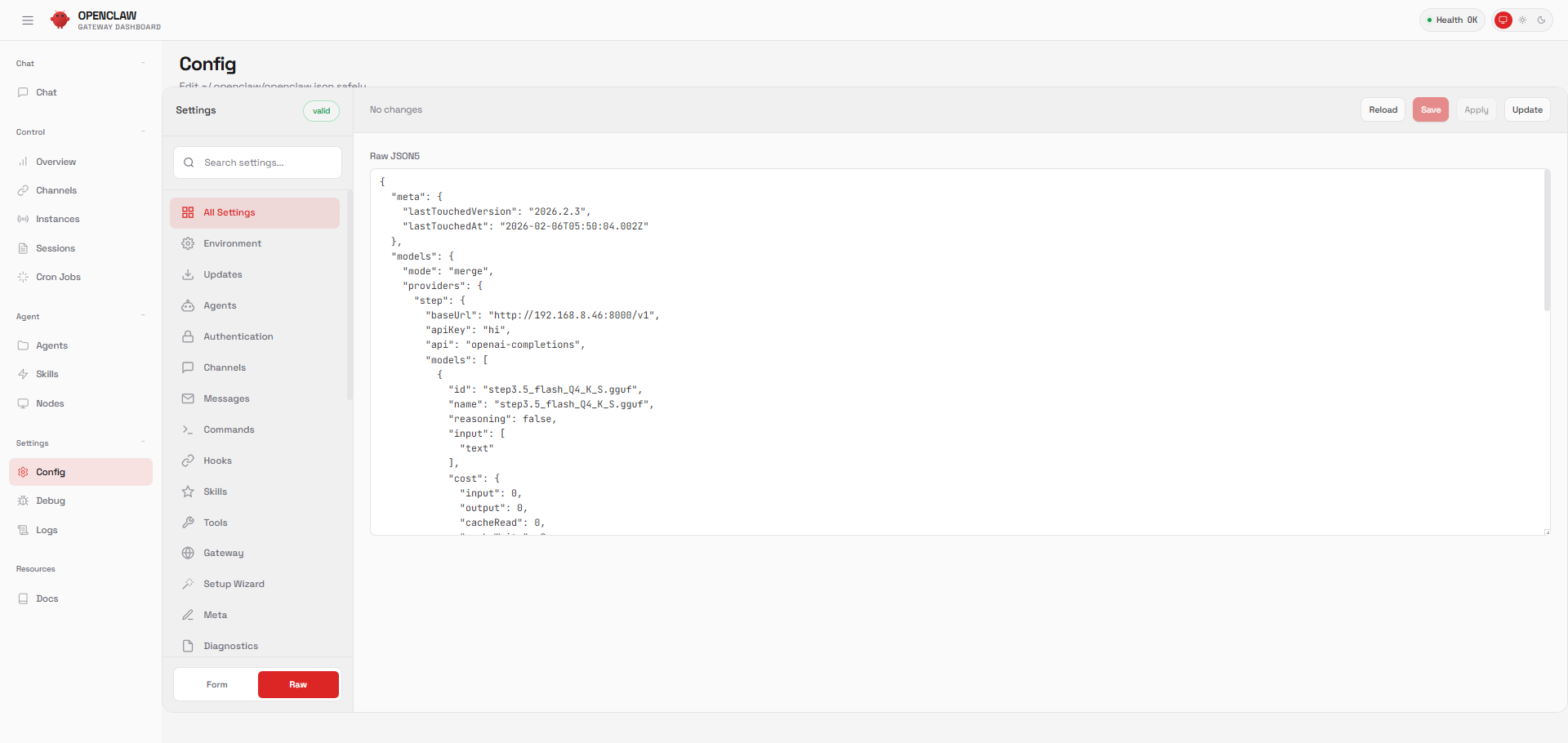
4.2 OpenClaw 接入本地大模型
添加本地大模型为模型提供商,并引入智能体首选默认模型
4.3 使用全栈私有的 OpenClaw
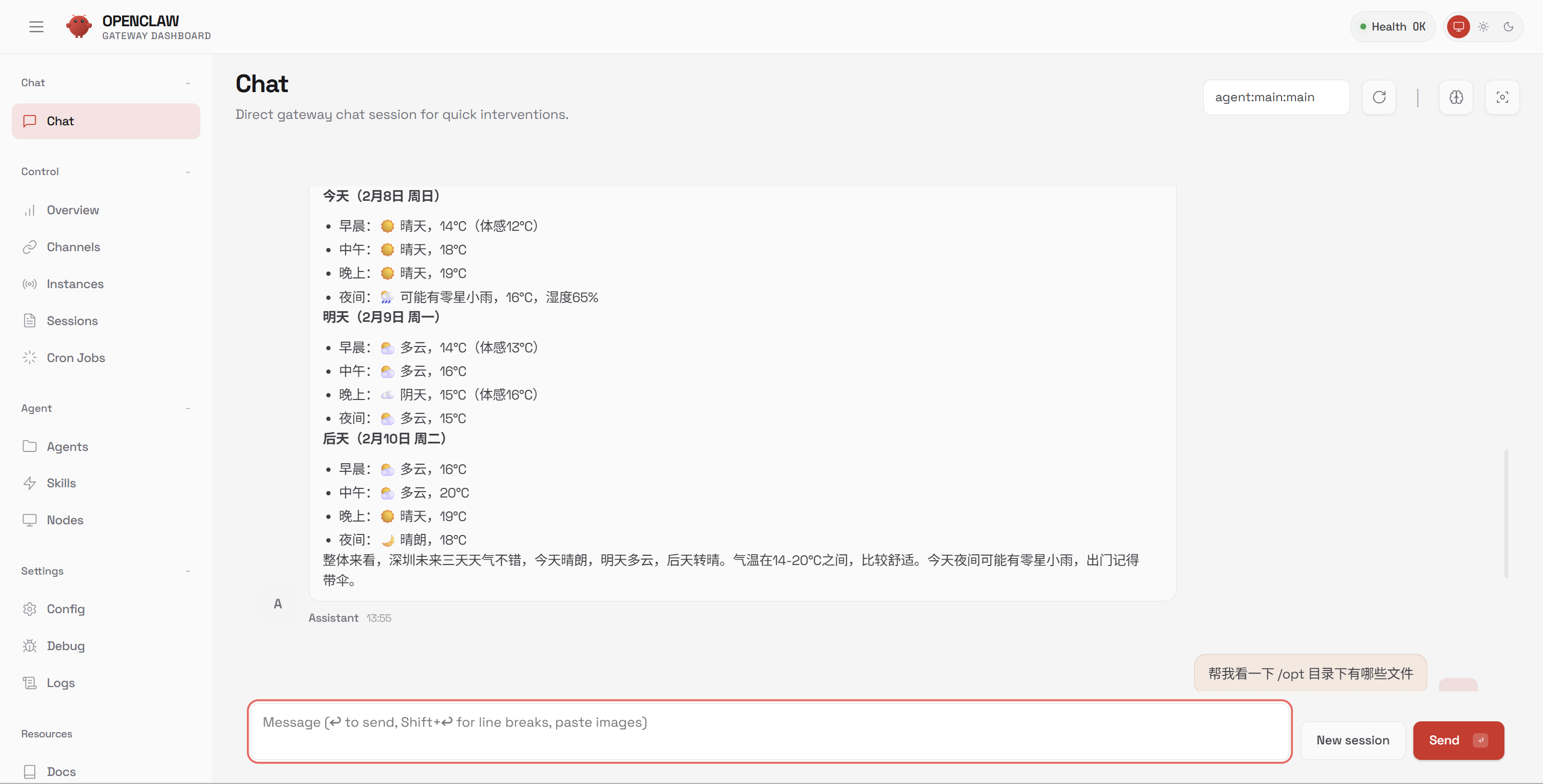
五、 结语
对于追求数据主权、自动化效率与长期运维成本的团队与个人而言,OpenClaw 搭配专属优化的本地模型底座,不再是 “可选方案”,而是私有化智能体时代的必然选择。当 AI 真正做到全程本地、自主执行、持续可用,我们才算真正迈入了 “让 AI 踏实干活” 的新阶段。而这套以 OpenClaw 为核心的全栈私有化架构,正是当下最贴近现实、也最具长期价值的最优解。
我们将持续跟进 OpenClaw 版本迭代、开源模型优化动态,同步更新推理引擎适配方案与算力底座优化技巧,及时补充不同硬件环境下的部署避坑指南。同时,也会跟踪国内开源生态与国产芯片的适配进展,助力更多团队低成本落地全栈私有化智能体,让 “数据自主可控、AI 高效干活” 的核心诉求,在每一个本地部署场景中得以实现,共同探索私有化智能体的更多应用可能。