.png)
一、背景
随着 AI Coding 在企业内网场景下的需求激增,越来越多的团队希望在内网环境中部署本地大模型,既保证代码和数据不出域,又获得高效的编程辅助能力。本文将详细介绍如何在一台服务器上,通过 1Panel 可视化部署 vLLM 推理引擎,并加载 Qwen3.6-27B 模型的全过程,同时详细解析每个核心配置参数的含义。
二、硬件及软件环境
本次使用的硬件服务器具体配置参见如下:
本次使用的软件环境
三、前置条件准备
在开始部署之前,先准备模型文件
3.1 检查 GPU 驱动
nvidia-smi
正常输出应显示 GPU 型号、驱动版本、CUDA 版本以及显存信息。
3.2 检查 Docker GPU 能力
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smi
如果正常输出 nvidia-smi 信息,说明 Docker 已具备 GPU 运行能力。
3.3 准备模型文件
提前将 Qwen3.6-27B 模型文件下载到服务器本地目录,例如:
# 从 Hugging Face 下载(有外网条件时预下载好)
# 或从一体机预装存储中获取
ls /models/Qwen3.6-27B/模型目录应包含以下关键文件:
config.json— 模型配置文件tokenizer.json/tokenizer_config.json— 分词器文件model-00001-of-XXXXX.safetensors— 分片模型权重文件*.py等相关代码文件
四、通过 1Panel 部署 vLLM
4.1 进入 vLLM 管理页面
打开 1Panel 面板,进入 AI → 模型 页面,切换到 vLLM 标签页,点击【创建】
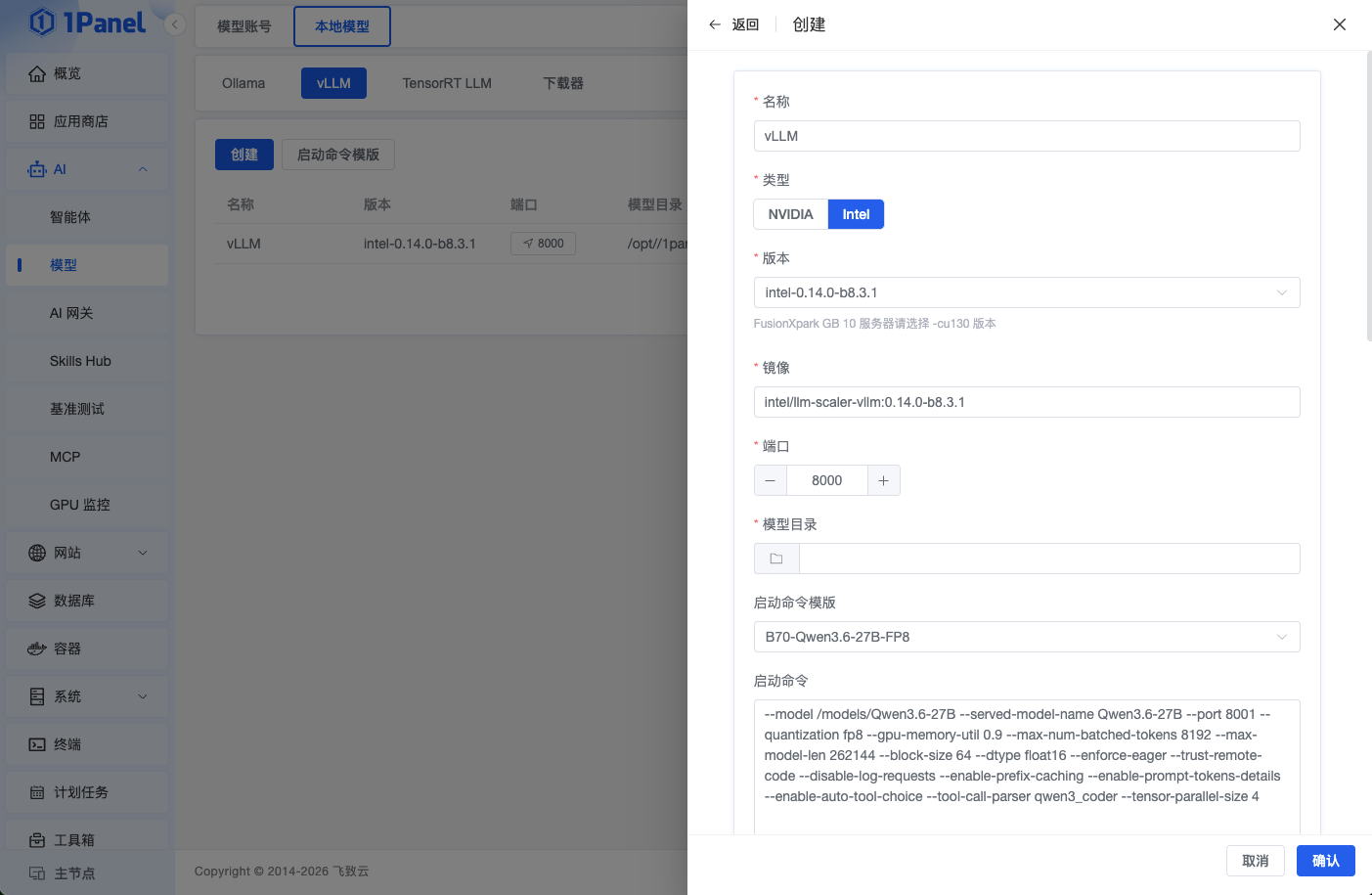
4.2 填写部署参数
在弹出的表单中,按以下配置填写:
4.3 启动命令详解
这是最关键的部分。完整的启动命令:
--model /models/Qwen3.6-27B
--served-model-name Qwen3.6-27B
--port 8000
--quantization fp8
--gpu-memory-util 0.9
--max-num-batched-tokens 8192
--max-model-len 262144
--block-size 64
--dtype float16
--enforce-eager
--trust-remote-code
--disable-log-requests
--enable-prefix-caching
--enable-prompt-tokens-details
--enable-auto-tool-choice
--tool-call-parser qwen3_coder
--tensor-parallel-size 4
下面逐一解析每个参数的含义:
4.3.1 模型路径与标识
4.3.2 服务端口
4.3.3 量化与精度
4.3.4 GPU 资源管理
4.3.5 上下文长度与批处理
4.3.6 推理优化
4.3.6 调试与日志
4.3.7 工具调用(Function Calling)
4.4 其它部署参数
4.5 点击确认
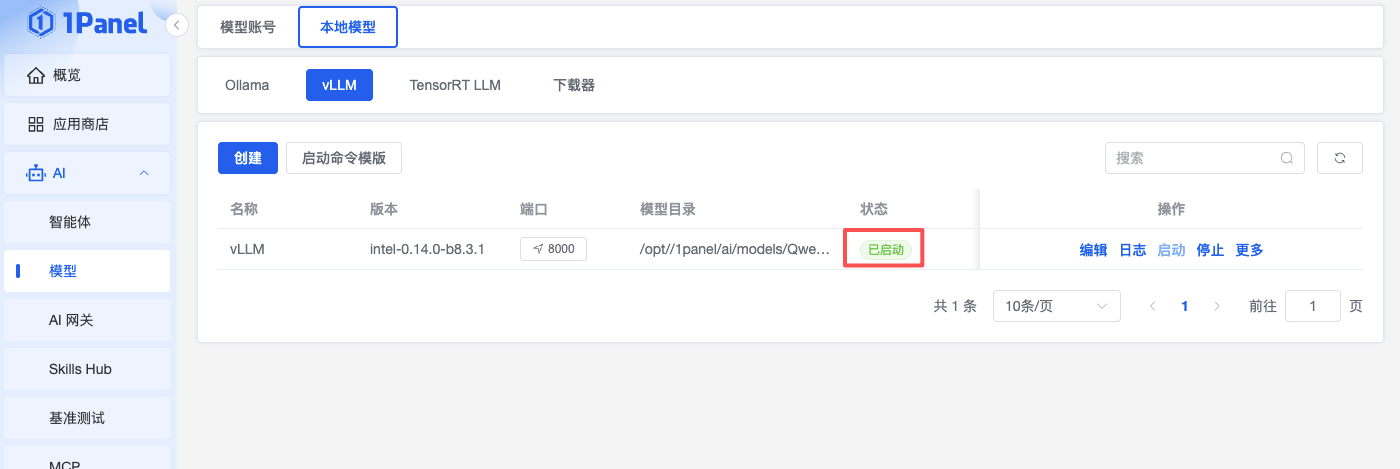
填写完成后,点击「确认」开始创建。1Panel 会在后台执行创建任务,包括拉取镜像、挂载模型目录、启动容器等。
等待任务完成后,在 vLLM 列表中可以看到服务状态变为「已启动」。
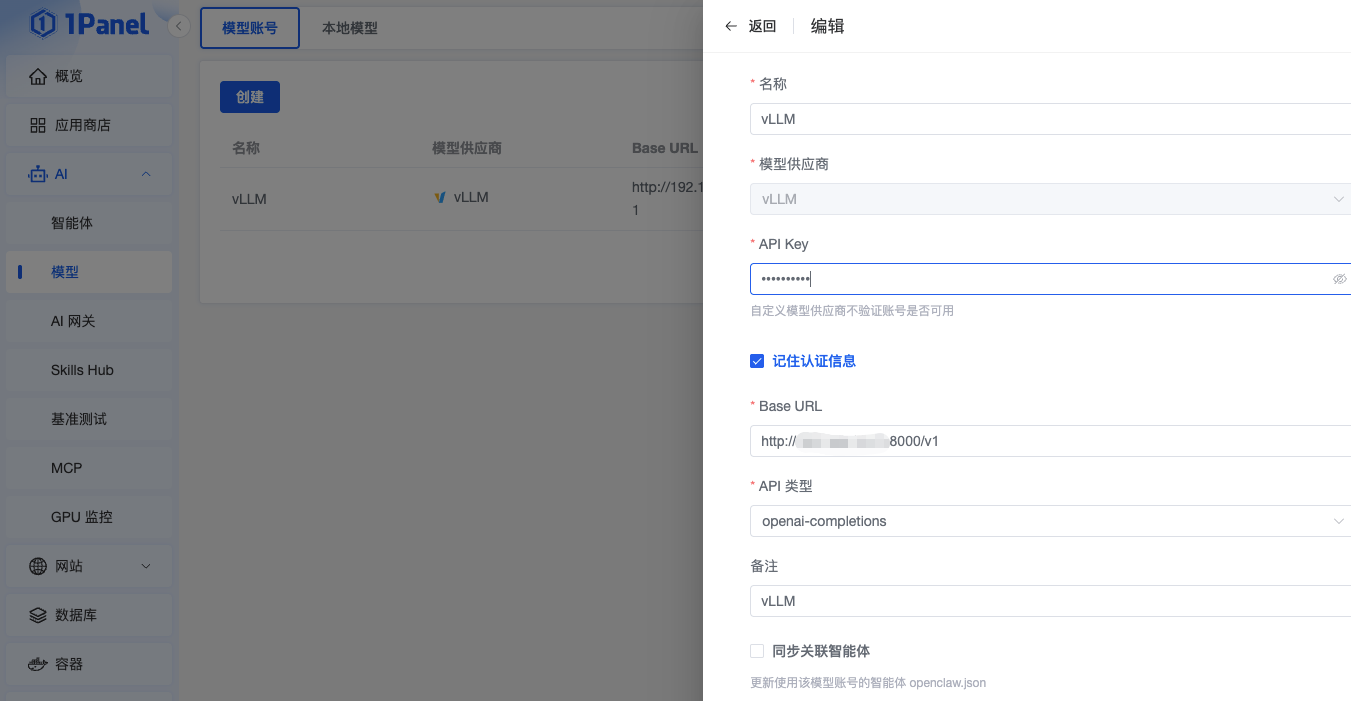
4.6 模型账号添加
进入模型账号点击创建,输入名称、选择模型供应商vLLM,输入任意字符作为API Key,同时输入当前模型部署对外访问的服务器IP地址以及端口号即可,API 类型选择openai-completions。参见如下图所示:
五、验证服务
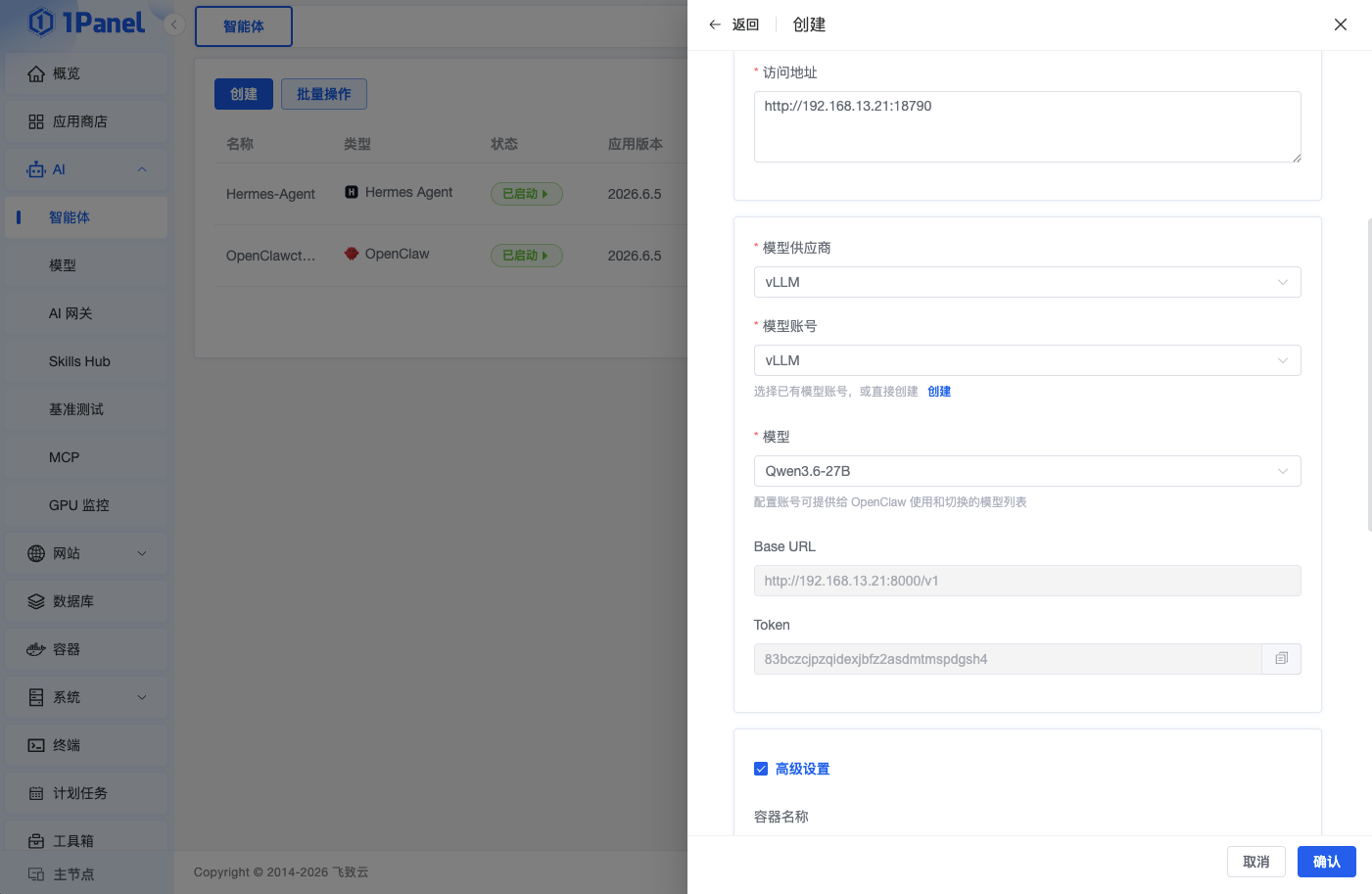
5.1 部署OpenClaw选择 vLLM 模型
进入AI模块的智能体模块,点击创建,选择OpenClaw ,输入基本参数后,选择模型供应商vLLM、vLLM的模型账号以及对应本地模型 Qwen 3.6-27B ,的具体参见如下图所示:
5.2 基于本地模型OpenClaw对话试用
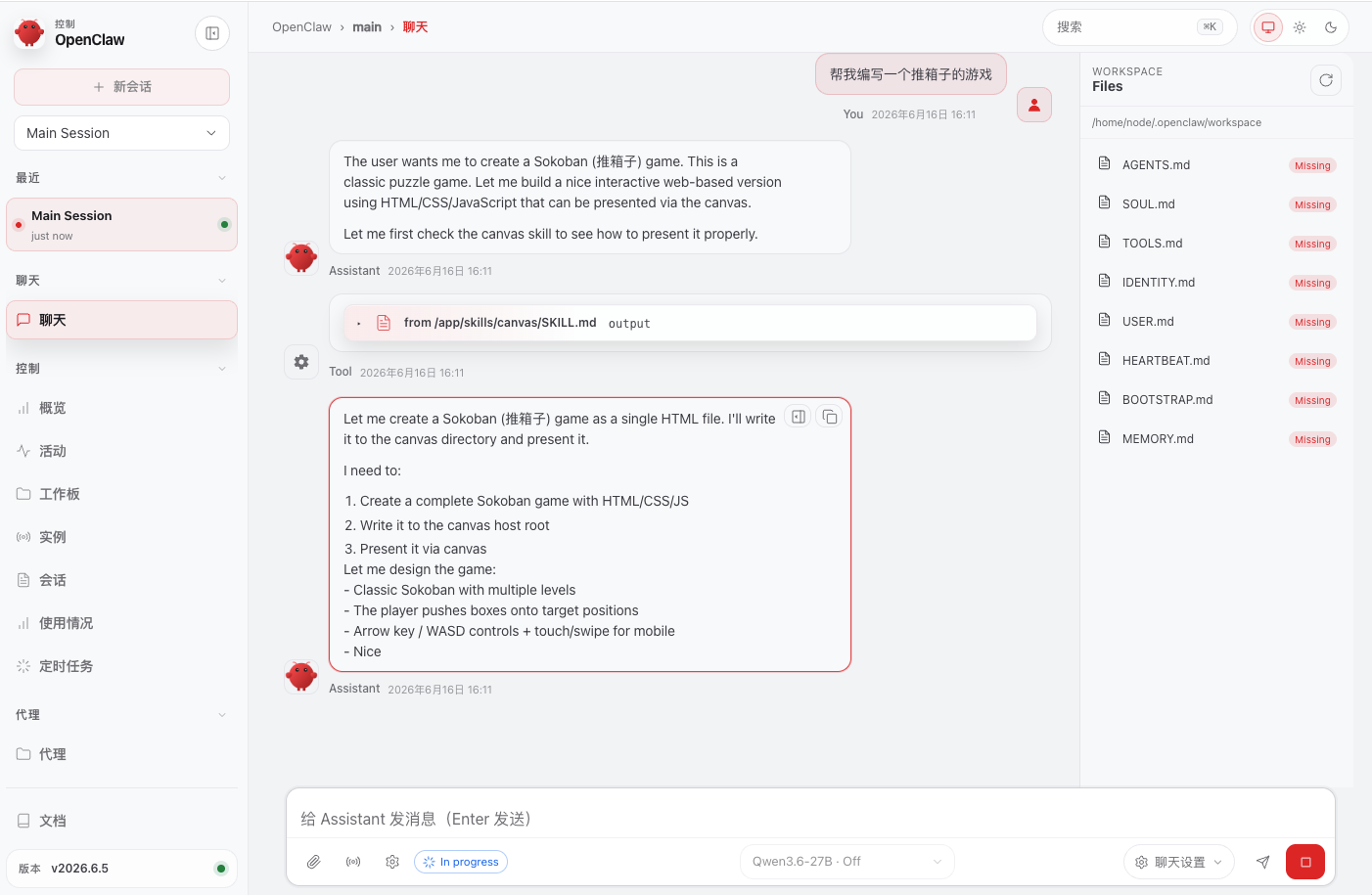
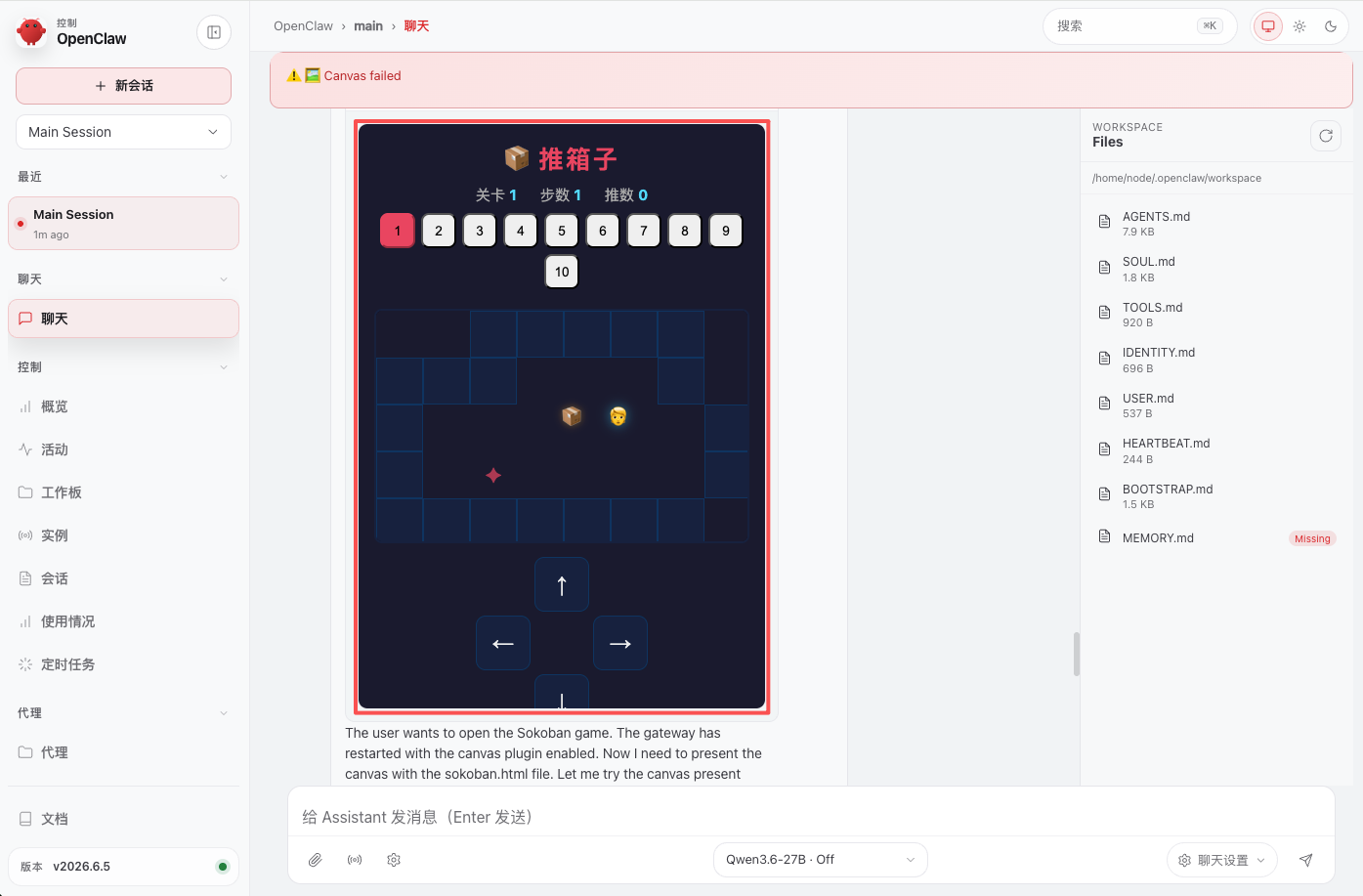
5.3 效果呈现
推箱子游戏:大概 1 分钟左右展示出成果。
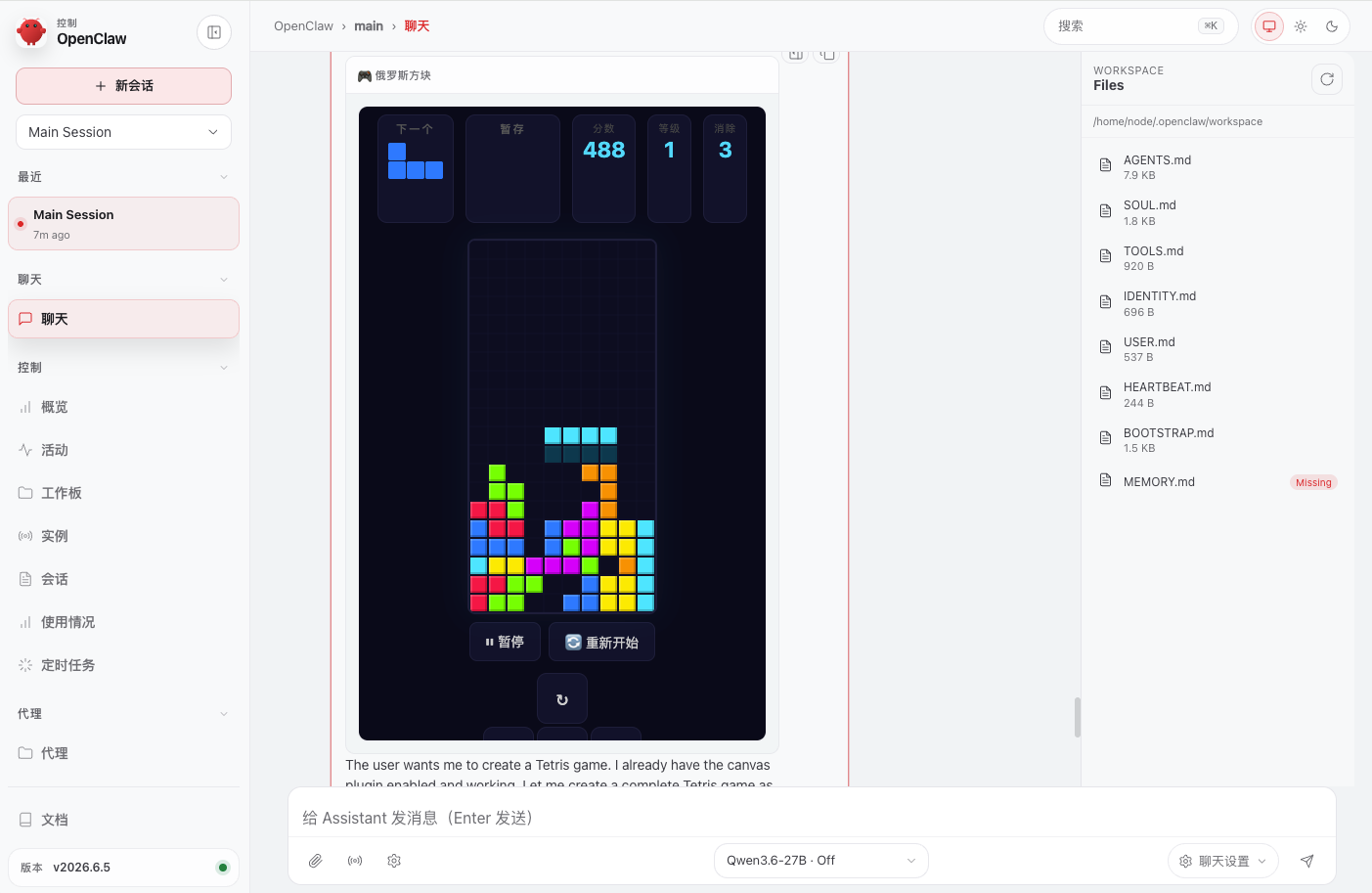
俄罗斯方块:用时大概 2-3 分钟
六、常用参数调优建议
场景一:追求吞吐量(多人并发)
--max-num-batched-tokens 16384 \
--gpu-memory-util 0.95 \
--block-size 128
场景二:追求低延迟(单人交互)
--max-num-seqs 1 \
--max-num-batched-tokens 4096 \
--block-size 32
场景三:支持超长上下文(代码仓库级)
--max-model-len 524288 \
--block-size 64 \
--enable-prefix-caching
⚠️ 超长上下文会显著增加显存占用,请确保 GPU 显存充足。
七、常见问题
Q1: 启动后报 "Out of memory"
原因: Qwen3.6-27B 量化后仍需较大显存,FP8 量化约需 16-18GB/卡。
解决:
降低
--gpu-memory-util到 0.8增加
--tensor-parallel-size使用更多 GPU 卡确认没有其他进程占用 GPU 显存
Q2: 模型加载速度很慢
原因: 首次加载需要从磁盘读取模型文件并初始化 KV cache。
解决:
确保模型文件放在 SSD 上
首次加载后后续重启会快很多
使用
--enforce-eager可跳过 Graph 编译时间
Q3: 工具调用格式解析错误
原因: 不同的模型需要不同的 tool call parser。
解决: 确认使用了 --tool-call-parser qwen3_coder,且模型确实支持 tool calling。
Q4: API 返回 503 Service Unavailable
原因: 模型尚未完全加载完成,或者正在处理前一个请求。
解决: 等待模型加载完成后再请求,通常需要 1-3 分钟。
九、总结
通过 1Panel 的可视化界面,我们可以轻松地部署 vLLM 推理服务并加载 Qwen3.6-27B 模型。整个过程只需以下几个步骤:
✅ 软硬件环境准备
✅ 将模型文件放置到本地目录
✅ 通过 1Panel UI 创建 vLLM 服务
✅ 填写启动命令和参数
✅ 启动验证并接入应用
核心参数 --quantization fp8、--tensor-parallel-size 4、--enable-prefix-caching、--enable-auto-tool-choice 等为 Qwen3.6-27B 在一体机上的最佳实践配置,确保了推理效率、上下文长度和工具调用能力的完美平衡。